Given a connected, undirected graph with non-negative edges, an MST (Minimum Spanning Tree) is a subgraph that fulfills the following conditions:
- spanning it connects all vertices (every node is reachable)
- acyclic it’s a tree thus it’s acyclic. If there was a cycle, we could remove the most expensive edge and it would remain an MST
- minimal the sum of the weights in is minimal, i.e. the smallest possible among all spanning trees of .
We can infer from the fact that we want the cost to be minimal, that the number of edges should also be minimal (otherwise we can again remove one). Therefore, the MST has only edges.
A safe edge is an edge that has to be included in all MSTs (if the edge-weights are distinct, which means there is one unique MST). Identifying them allows us to iteratively build such a tree.
Restrictions on the Graph for an MST to exist
The graph needs to be connected, otherwise we can only find an MSF, a minimum spanning forest of disconnected trees.
A graph for which we want to find an MST does not need to have positive edge-weights.
Even though Prim’s algorithm is similar to Dijkstra’s there’s no restrictions for edge-cost as we don’t use the triangle inequality.
Schnittprinzip (Cut Property)
To join a set of disjoint connected components, we need to use an edge to join two of their vertices. The idea is that the cheapest such edge is always a safe edge.
Proof Idea: We can use a cut&paste argument to prove the cut property. Let be any cut of a graph . Let be the minimal edge crossing this cut. We want to show that .
- Assume for contradiction.
- Since is a spanning tree, contains a cycle, crossing the cut at least twice (once via and once via another edge .)
- We now construct which breaks the cycle but keeps the MST property.
- Since , and thus is not an MST.
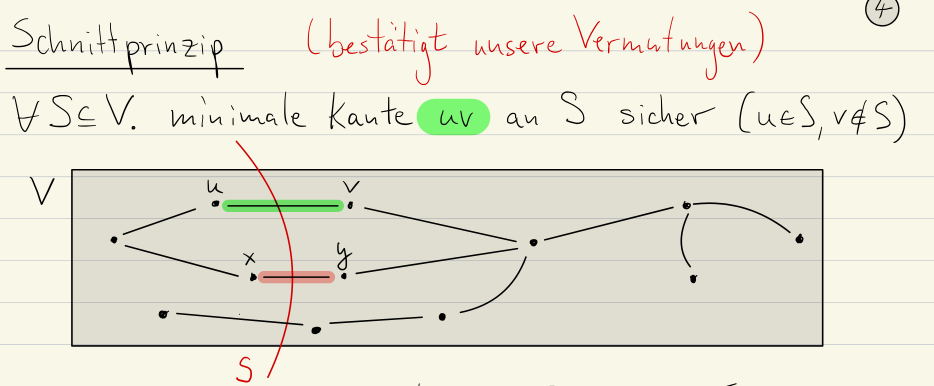
A locally minimal edge is an edge that is the cheapest connection between a vertex and any vertex outside it’s immediate neighbourhood. This is the more local version of the Schnittprinzip.
Thus our idea for constructing an MST will be to start with and iteratively add safe edges.
The fact that the cut property is both locally and globally optimal allows us to use greedy algorithms, unlike in the cheapest path problem.
Boruvka’s Algorithm
Runtime:
Restrictions: undirected, weighted, connected graph
Usage: Build an MST
For the correctness of Boruvka, we assume that all edges have distinct weights (in the real world we could use an id or something else to break ties).
- For Boruvka, we start with the set of edges . We treat each of the isolated vertices of the graph as it’s own connected component.
- Each vertex marks it’s cheapest outgoing edge as a safe edge (making use of the cut property). We add these to .
- Note that some of the edges might be chosen by both adjacent vertices, we still only add them once.

- Now, repeat by finding the cheapest outgoing edge for each component. Do this until all are connected.
- constitutes the edges of the MST.
Code
Boruvka(G):
F = ∅ # Set of MST edges
Components = {{v} for v in V} # Initially, each vertex is its own component
while |Components| > 1:
SafeEdges = ∅
for each component C in Components:
cheapestEdge = findCheapestEdge(C, G) # finds the edge with minimum weight connecting C
# to another component. Returns None if it doesn't exist.
if cheapestEdge is not None:
SafeEdges.add(cheapestEdge)
for edge (u,v) in SafeEdges:
Components = mergeComponents(Components, u, v) # Merges components containing u and v
if (v,u) not in F: # prevent duplicate edges
F = F ∪ {(u, v)}
return FNote that this algorithm is parallelisable.
Runtime
For each iteration, we need to examine all edges to find the cheapest one: (calculate connected components with DFS: and then go through each one to find minimal).
We iterate a total of times, as each iteration joins at least two halves.
Total runtime is .
We assume efficient datastructures for managing connected components and finding the minimum edges.
Prim’s Algorithm
Runtime:
Restrictions: undirected, weighted, connected graph
Usage: Finding an MST
Prim’s algorithm starts with a single vertex and grows the MST outwards from that seed.
- Initialisation:
- Select and arbitrary starting vertex and empty set
- Set tracks the vertices in the MST
- Each vertex gets a
key[v] =representing the cheapest known connection cost to :- if no edge connects to
- if edge exists
- Use a priority queue (Min-Heap) to store the vertices, in order of lowest
keycost
- Iteration:
- Select and add Extract the vertex with the minimum
keyfrom . This is the cheapest to connected to the current MST. Add to . - Update Neighbours For each neighbour of not in :
- If update
key[v] = w(u, v)and update the priority in .- This discovers potentially cheaper connections to vertices outside the current MST. If a cheaper edge to is found, the current value in
key[v]cannot be part of the MST
- This discovers potentially cheaper connections to vertices outside the current MST. If a cheaper edge to is found, the current value in
- If update
- Select and add Extract the vertex with the minimum
- Termination: When is empty, all vertices are in and connected, and the edges chosen are in the MST (tracked in the set through updates).
Algorithm
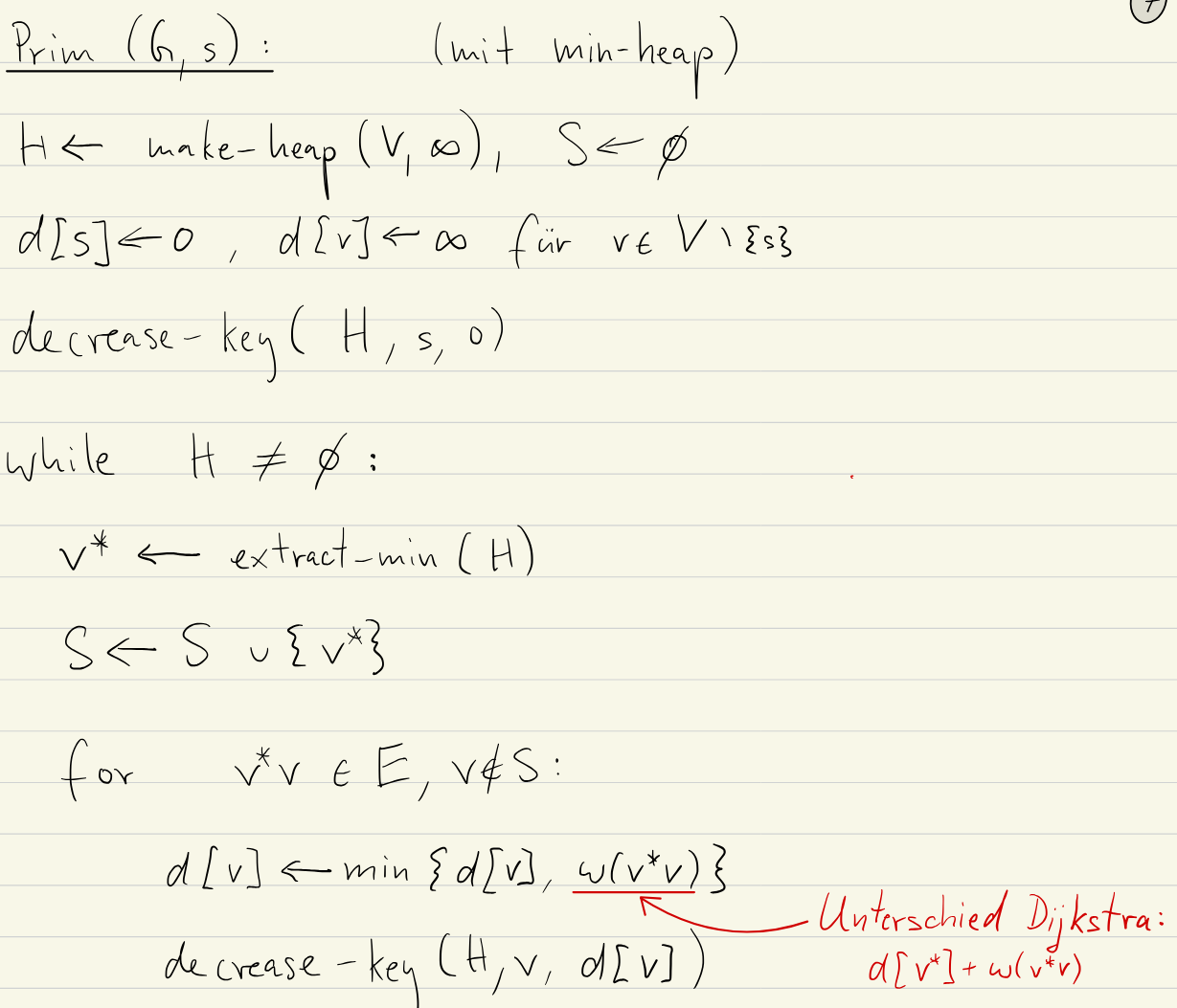
Runtime
Using a binary heap as the priority queue, Prim’s algorithm has a runtime of (like Dijkstra’s and Boruvka’s).
Difference to Dijkstra’s
We update the distance for each node not in the MST yet as the smallest distance to any node in the MST (to find a safe-edge, the on./e with the smallest weight).
This is in comparison to Dijkstra’s, where as we track total distance to the starting vertex.
Invariants holding for Prim’s
The following invariants hold during execution:
- The priority queue ( set of all vertices, vertices currently in the MST). Priority queue never contains a vertex already in the MST.
- The distances
d[.] =in the distance array are the values of the vertices in the priority queue. (see linedecrease_key(H, v, d[v])) - , ( if no such edge exists)
The 3rd invariant
ensures that d[v] always reflects the minimum cost to reach vertex v from the current MST.
We always want to add the vertex with the cheapest edge connecting it to the MST, thus this invariant has to hold in order for the algorithm to be correct.
Kruskal’s Algorithm
Runtime:
Constraints: Undirected, weighted, connected graph (distinct edge weights)
Note that some sources say , as we assume that . Use the non-simplified version as in unconnected graphs it might be wrong.
Because the cheapest edge in the entire graph is always a safe edge, Kruskal iteratively builds out the tree from the cheapest edges.
We have to be careful not to add edges that would form a cycle as they are not in the MST.
Thus Kruskal only considers edges that connect new vertices to the MST.
Algorithm
def kruskal(G):
F = set() # Use a set for efficient cycle detection
for (u, v, weight) in sorted(G.edges(data='weight')): # Access weight data directly
if find(u) != find(v):
union(u, v)
F.add((u, v))
return F- Initialisation: Start with an empty set to represent the MST edges. Initially each vertex is it’s own seperate ZHK.
- Iteration:
- Sort all edges in the graphs by weight in increasing order.
- For each edge in sorted order:
- If adding does not create a cycle (i.e. and in different ZHKs)
- Add to .
- Merge the ZHKs of and
- If adding does not create a cycle (i.e. and in different ZHKs)
The operation of checking if there is no cycle can be done efficiently using the check of and being in different ZHKs. This can be done efficiently using the Union-Find datastructure.
Proof
Induction:
- BC: After adding 0 edges, each vertex is it’s own ZHK
- IH: Assume that after adding edges, is a subset of some MST
- IS: Let be the th edge.
- If adding creates a cycle, it’s discarded. IH holds.
- If there’s no cycle:
- connects two different ZHKs
- As it’s the cheapest, by ordering of edges, that crosses this cut, by the cut-property, it belongs to some MST. Therefore adding it to maintains the IH.
Runtime
Outer Loop: Kruskal’s iterates at most times:
Inner Loop:
- without union-find: checking for cycles requires a graph traversal for each edge, taking per edge for total
- With union-find:
findanduniontake an amortised per call and over all iterations it takes (asunionis amortised andfindis constant)
A dominant factor with union-find becomes edge-sorting, which takes .
Therefore the overall complexity is .
Union Find
The Union-Find datastructure provides 3 methods:
make(V): creates the DS forsame(u, v): tests if and are in the same component ofunion(u, v): merge ZHKs in of and (called when adding the edge from to )
The DS represents each ZHK using a representative in memory, rep[u]. Each vertex in the same ZHK has the same representative.
- Then
makeinitialises all ,rep[v] = v, this takes - A
samecheck compares representativesrep[u] == rep[v], this takes
After adding edges to the forest, the array repr contains exactly different representative values. Each added edge removes one unconnected component.
Merging by iteration
A naive way to merge two ZHKs would be to iterate over all vertices with the same representative and set it to the new one.
# Merge u and v
for x in V:
if rep[x] == rep[u] # check if x in ZHK of u
rep[x] = rep[v] # set x to same rep. as vThis takes per merge, which is very inefficient, as it has to be called each iteration.
Merging using membership lists
We introduce members[r], which contains all members of the ZHK with representative r.
# merge u and v
for x in members[r]:
rep[x] = rep[v]
members[rep[v]] = members[rep[v]] + [x] # add to members of ZHK vThis takes time (number of members of the ZHK). In the worst case, we take the MST of a “linear” graph, which means we always change ‘s ZHK in the th iteration.
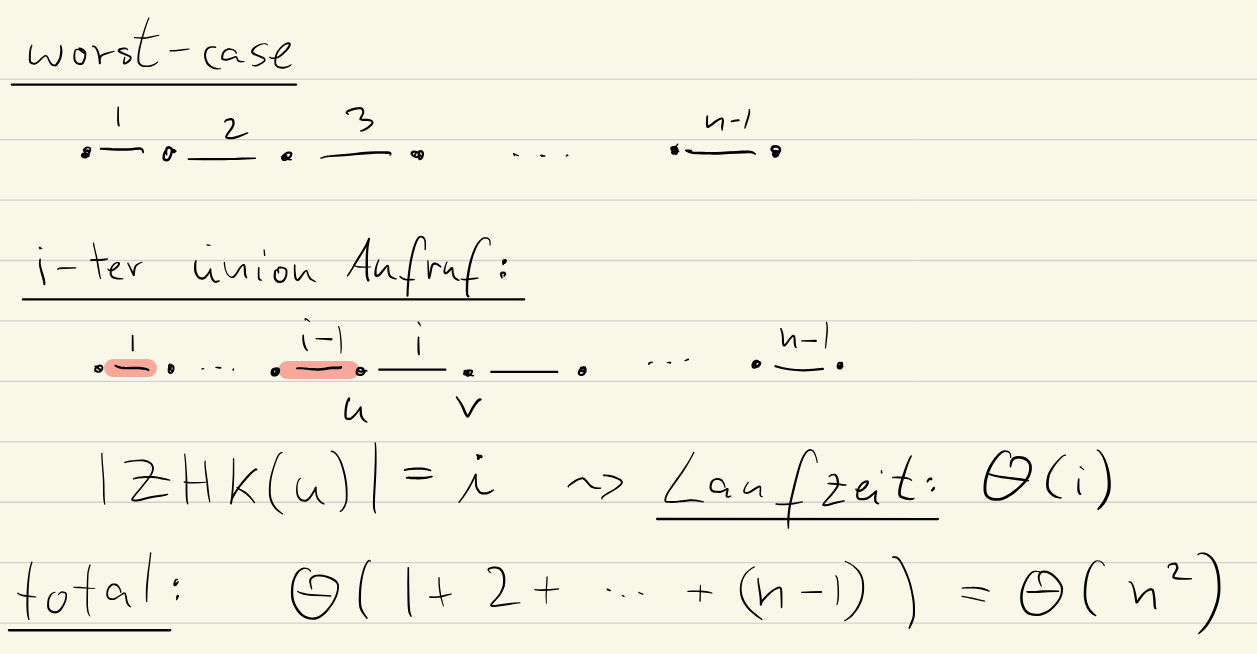
Merging by rank (members based)
We can improve on this by merging the smaller ZHK into the bigger one. This means that we perform the least updates possible.
By storing rank[r] for each ZHK, we can compare sizes.
if size[rep[u]] < size[rep[v]]:
for x in members[rep[u]]:
rep[x] = rep[v]
members[rep[v]] = members[rep[v]] ∪ {x}
size[rep[v]] = size[rep[v]] + size[rep[u]]
else:
for x in members[rep[v]]:
rep[x] = rep[u]
members[rep[u]] = members[rep[u]] ∪ {x}
size[rep[u]] = size[rep[u]] + size[rep[v]]
Now union takes . In the worst case, the minimum is as both have the same size.
Therefore over all loops, this would take time, as on average we only take time.
The graph stays worst case, this is the average of the calls in the worst case.
Proof: We count the number of times rep[u] changes to estimate runtime:
- If
rep[u]changes,- thus size of the ZHK of is always at least doubled.
- As the maximum size of a ZHK is , we need calls.
Runtimes
In any connected graph, thus and therefore, the MST algorithms all take time.