The software (compiler) organises instructions that can be executed in parallel into a single very long instruction (512 bits to 1024 bits for example).
→ it bundles base instructions
The bundled instructions can be completely unrelated, not like in SIMD.
The CPU trusts the compiler and executes all of them at the same time.
It uses a pipeline kind of like a superscalar pipeline except no conflict checking.
Pros:
- simpler hardware
- no need for dependency checking
- no need for instruction alignment/distribution to different functional units
Cons:
- compiler needs to be very good
- need to compile for hardware very specifically → tied to performance of the uarch
- low parallelism → code bloat
- a lot of NOPs
- lockstep-execution if any instruction in a VLIW stalls → all others stalls
- happens often with memory instructions
- in OoO-Execution we could work around this by then scheduling others → latency tolerance
18.2 Trace / Superblock optimisations
The VLIW architecture forces compiler designers to implement optimisation techniques to really take advantage of the parallelism.
- Trace Scheduling
- Superblock scheduling
These aim to identify and optimise frequently executed path in the control flow by creating larger, straight-line code blocks.
→ static scheduling and parallelisation
In this example we create a superblock.
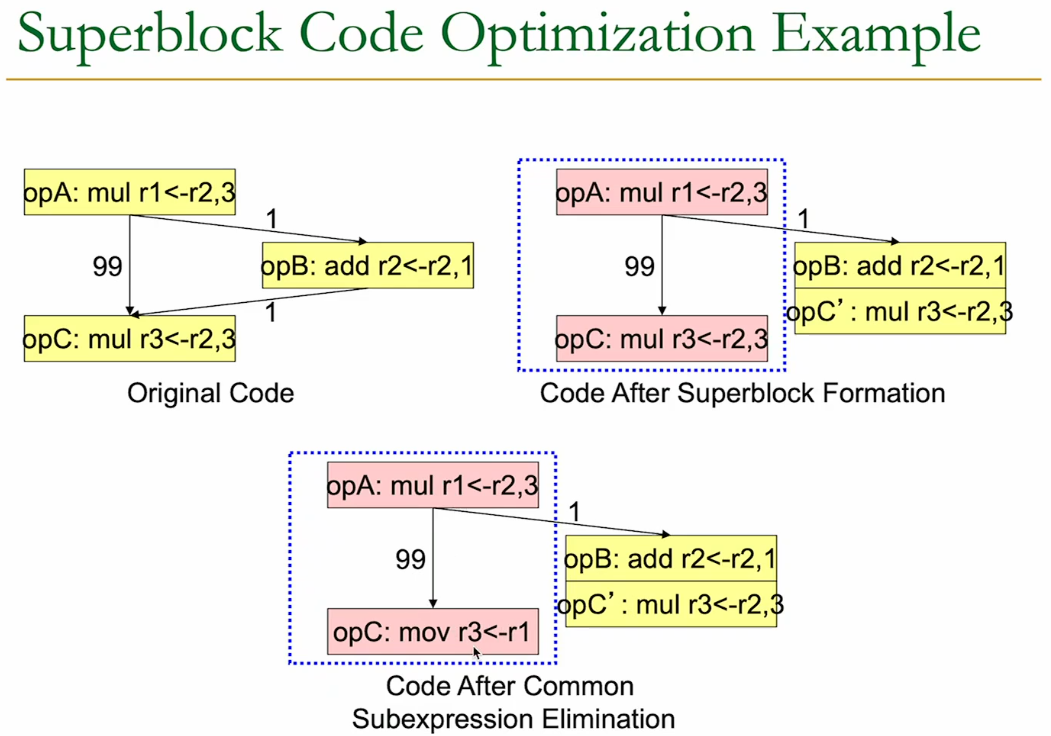
It has:
- a “hot-path”
- tail-duplication
- we might have to abort the block because of an unexpected branch
- for each possible branch out, we append the code that still needs to be executed to the end
- strength reduction
- use a
movinstead of a secondmul - find common subexpressions like
<-r2,3
- use a