20.1 Flynn’s Taxonomy
Flynn’s Taxonomy (introduced by Michael Flynn in 1966) classifies architectures based on the number of instruction streams and data streams processed concurrently:
- SISD (Single Instruction, Single Data): Traditional scalar processors, executing one instruction on one data element at a time.
- SIMD (Single Instruction, Multiple Data): Executes a single instruction on multiple data elements simultaneously. This is the focus of this lecture.
- MISD (Multiple Instruction, Single Data): Executes multiple instructions on a single data stream.
- similar to generalised Systolic computation
- MIMD (Multiple Instruction, Multiple Data): Executes multiple independent instruction streams on multiple data streams. This includes multiprocessors and multithreaded processors.

20.2 SIMD
Concurrency arises from performing the same operation on different pieces of data.
We reduce the number dynamic instructions using SIMD → less overhead (fetching, decoding).

Most modern processors actually use both array and vector processors.
- we can use array processors where each PE is actually a vector processor
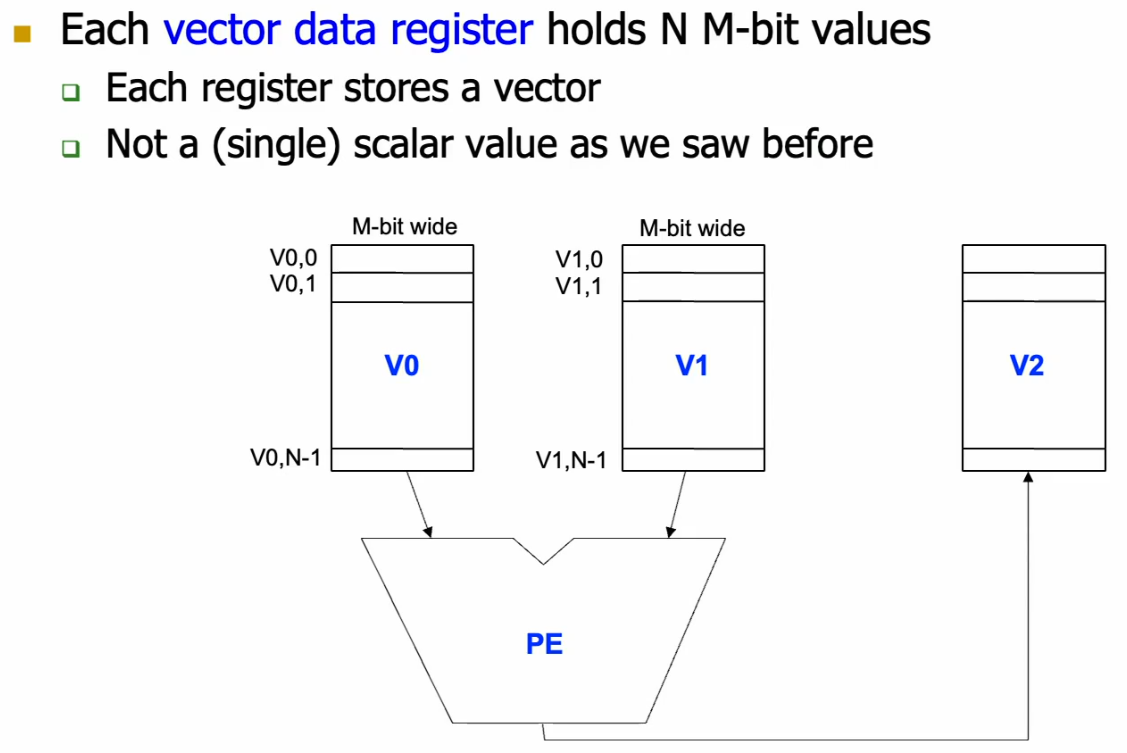
20.2.1 Vector Registers
We store the elements to be operated on in parallel in vector data registers (MxN elements).
Example Execution trace
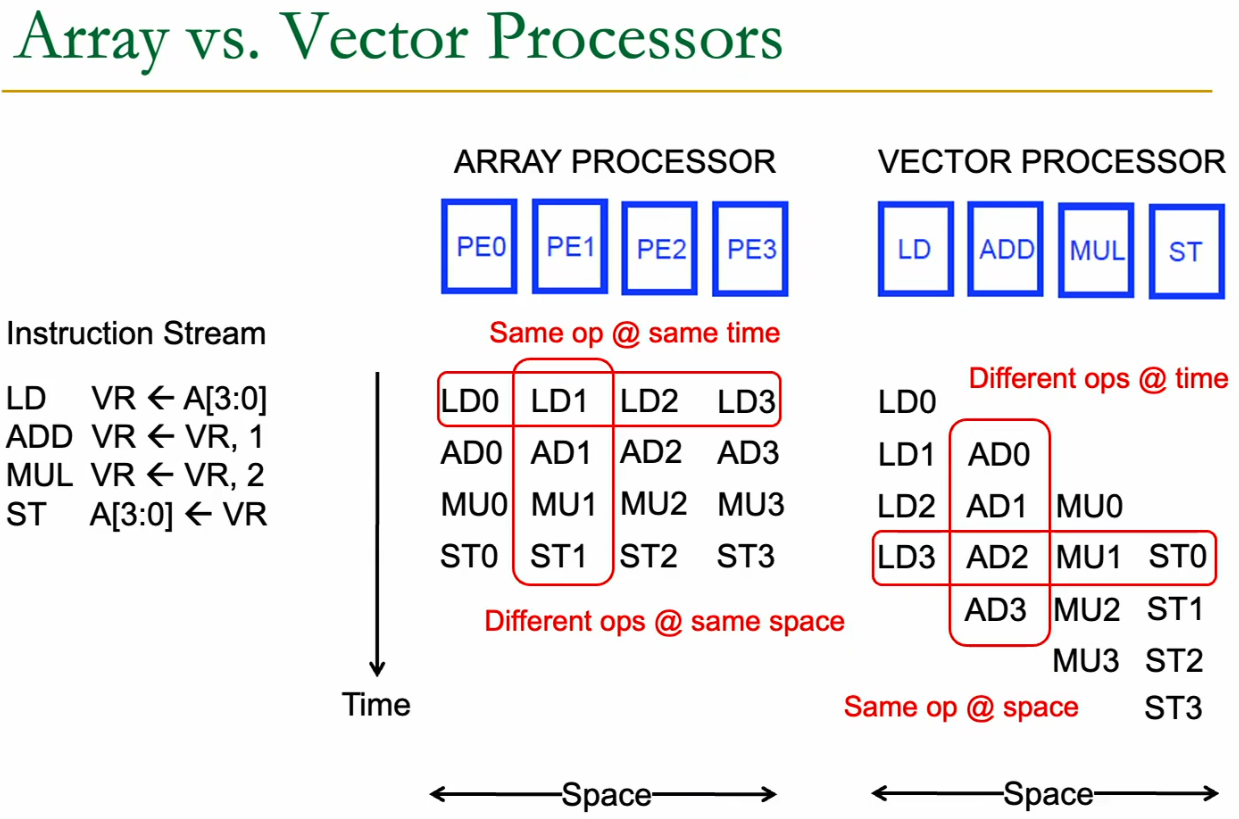
20.2.2 Array Processor
Every single PE is capable of executing all the instructions. They execute them in parellel, each operating on a different element of the vector (array).
For 4 instructions, we’ll run for 4 cycles and be done.
20.2.3 Vector processor
Kind of like a vector pipeline (systolic). Every PE performs only a single instruction, we operate on the data in a serial fashion.
Better cost efficiency as we don’t need to have that many PEs which are duplicate. Initially more used.
This allows deep pipelining. In normal pipelining we avoid deep pipelining because of costs on hazards. With vector processing we get:
- in vector processing, there are no intra-vector dependencies
- no control flow within a vector
- known stride allows easy address calculation
We can be limited by memory bandwidth very easily however → Stalling everything.
Vector masks: using a vector mask we can implement “branching” → only operate the instruction on certain elements on the vector.
Vectorizable
A loop is vectorizable if each operation is independent of any other.
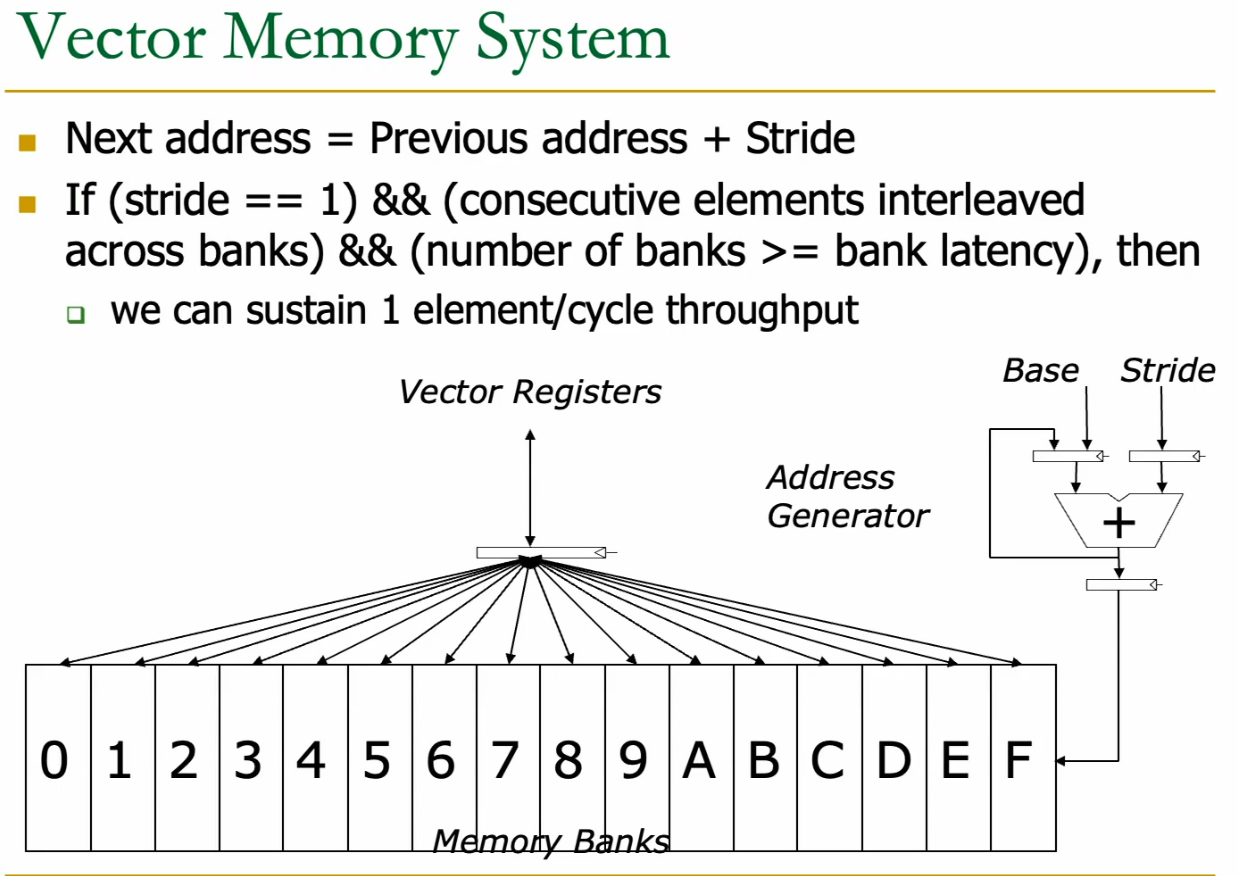
20.2 Memory Accesses for Vectors
We need 1 element per cycle for maximum throughput.
Memory Banking
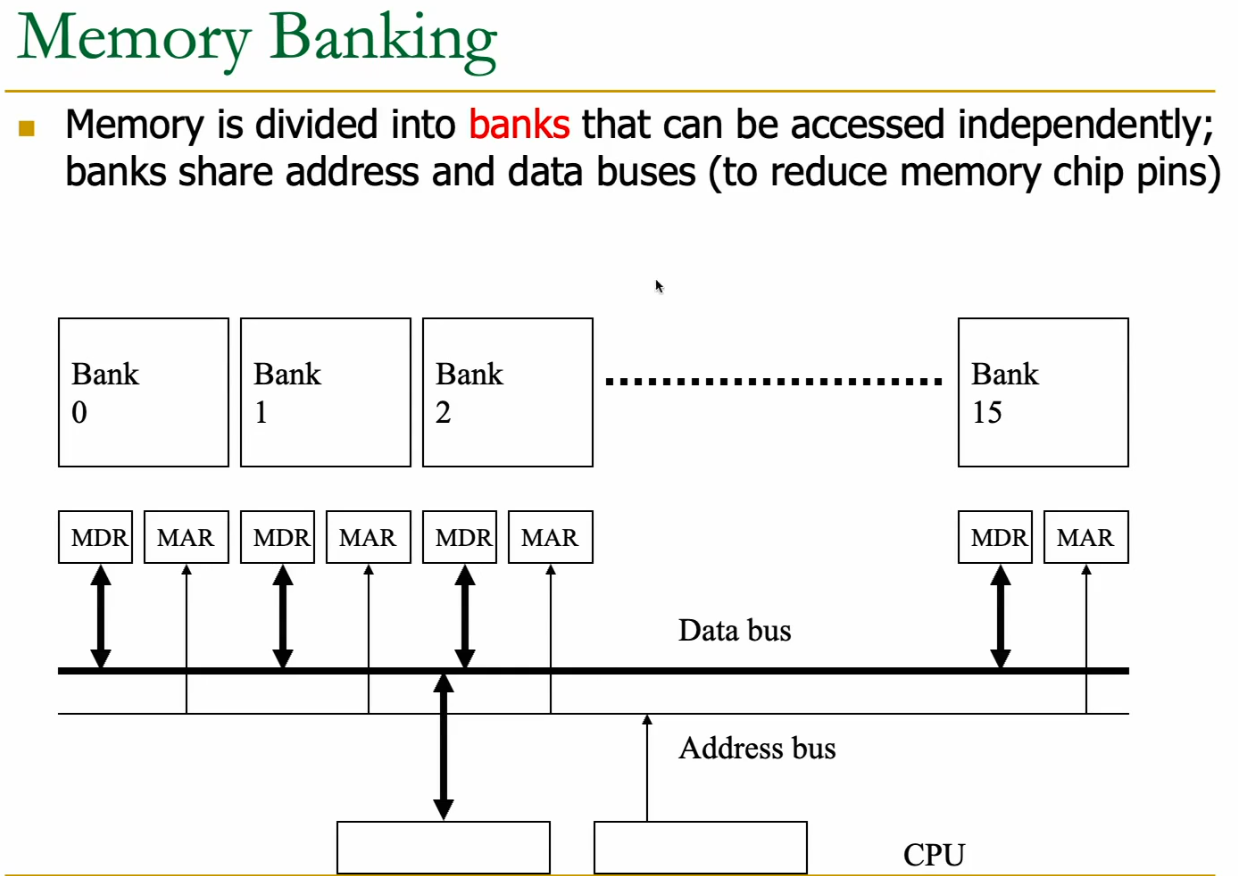
divide memory into banks
→ each bank can be accesses independently (has it’s own controller and pins)
Since memory access takes many cycles, we have to interleave the vector elements across these banks. Then we can cycle across the banks to fetch 1 from memory per cycle.
Because we basically “stream the data in”, we can have the data separated across banks be pulled in JIT:
20.2.2 Vector Chaining
Instead of loading from memory, we forward the data from one vector functional unit to another.
We can stream the data between the units. Can already start processing previous elements.
20.2.3 Vector Stripmining
If we have more vector elements than the vector register supports.
We split our data into individual blocks (if VREG is 64 bits wide) we process in 64 bits block until we have < 64 bits left. Then one final call.
20.2.4 Unstrided data
If we have vector data that is not stored in a strided fashion (irregular access to a vector)
- use indirection to pack them
→ scatter / gather operations
This can also be employed to avoid useless computations in sparse matrixes → repack them.
Gather operation There is a special operation that loads indirectly

Scatter Operation We can store these packed elements back into irregular memory addresses using scatter → adds offset for each element and leaves all other locations untouched.
20.2.5 Masking
To have branching in the code, we can use masking:

Simple execute all instructions, only store back those where mask is on
Density-Time Implementation scan mask vector and only execute elements with non-zero masks.
→ better for masks with lots of elements blocked out
20.2.6 Bank conflicts
Stride and register size relatively prime → guarantees permutation = no conflicts.
Different strides lead to bank conflicts. If we multiply vector A and B → A with stride 1 and B with 10 (row vs. column major for example) we will get conflicts.
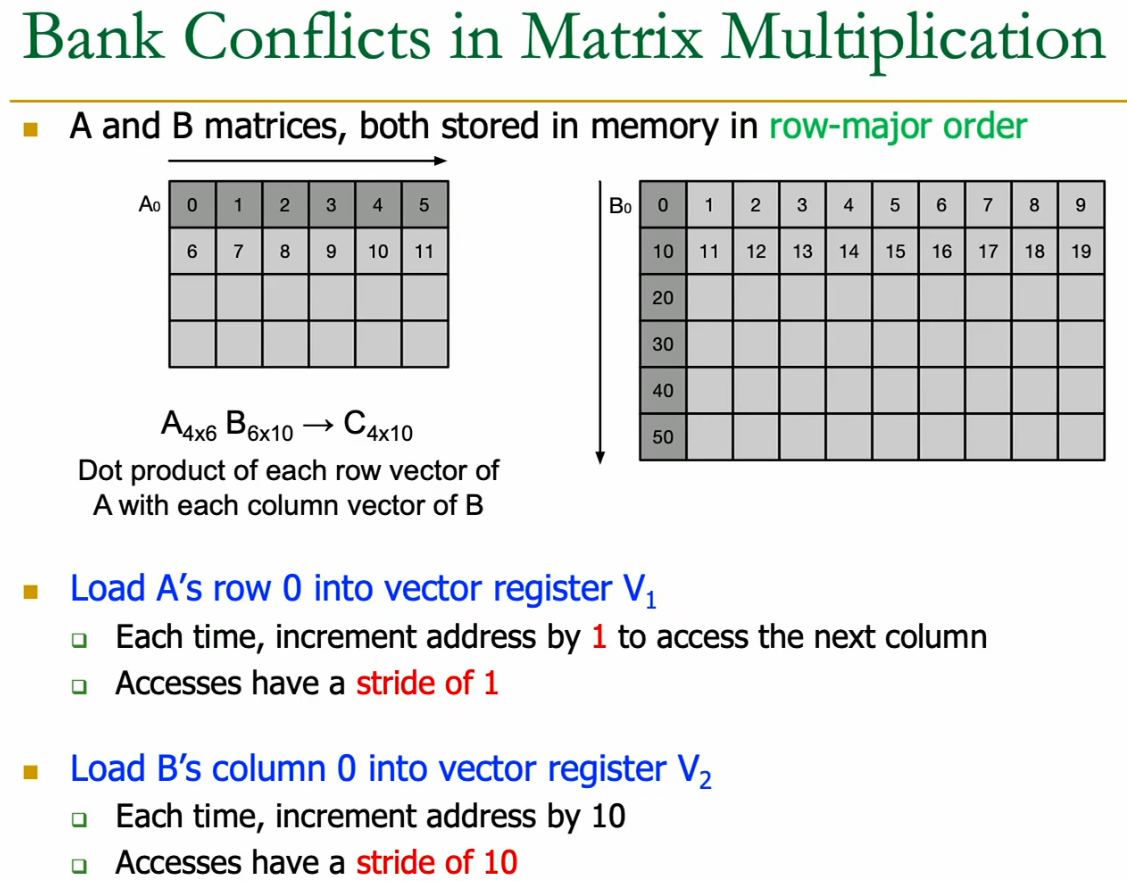
Fix
- more banks
- more ports in each bank
- better data layout
- not always possible
- better mappping of address to bank
- randomized mapping
20.3 Cerebras
MIMD → each tile on the die computes in parallel, different instructions
Then inside each tile there is SIMD, to accelerate things.