GPUs are SIMD Engines underneath.
However, the programming is done using threads, not SIMD instructions.
→ threads do the same thing, on different data

GPUs have a nice programming model → hardware matches it nicely: SPMD.
21.0 Different Ways to Exploit Parallelism
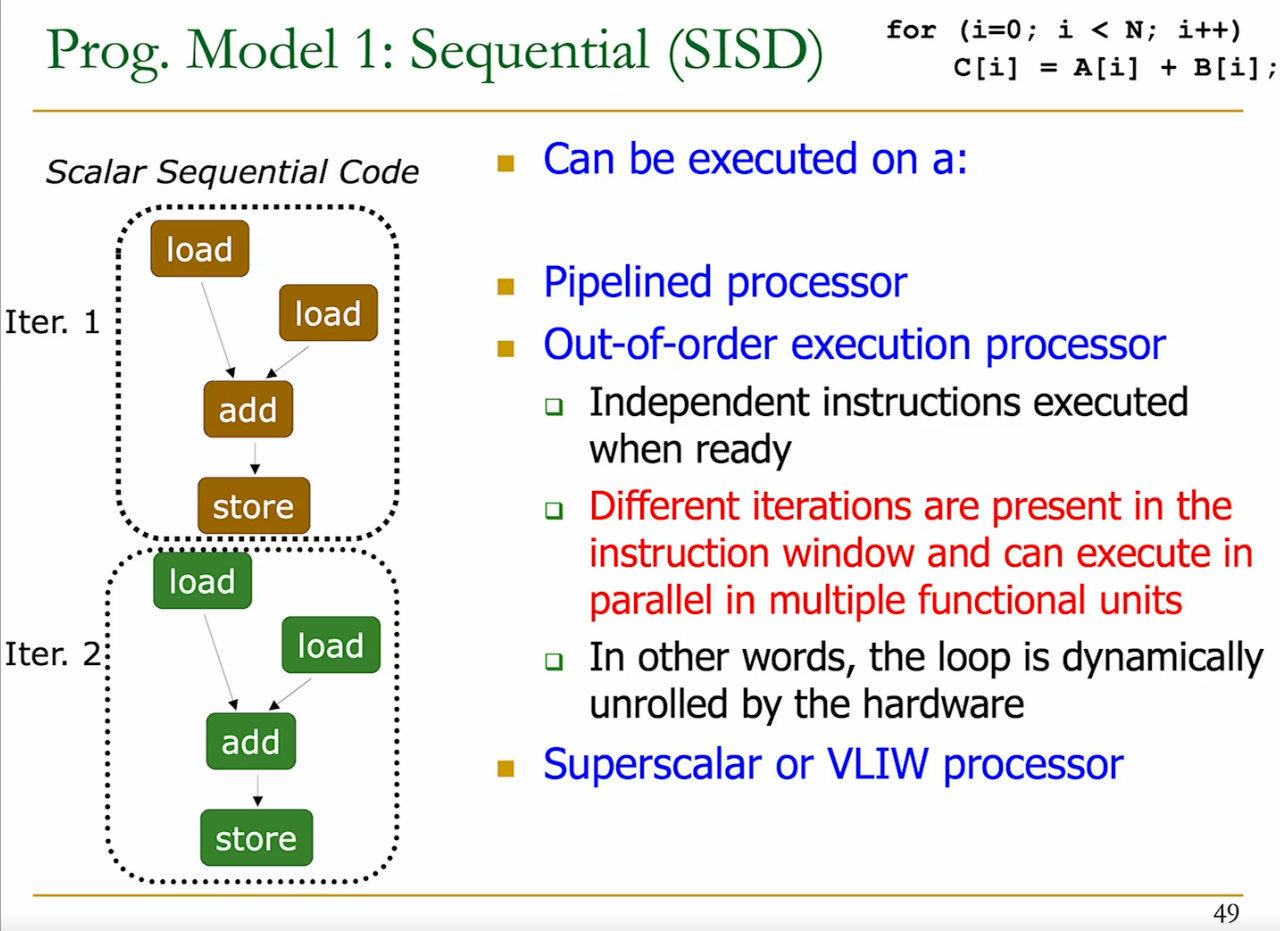
1 - SISD (Sequential)
2 - SIMD:
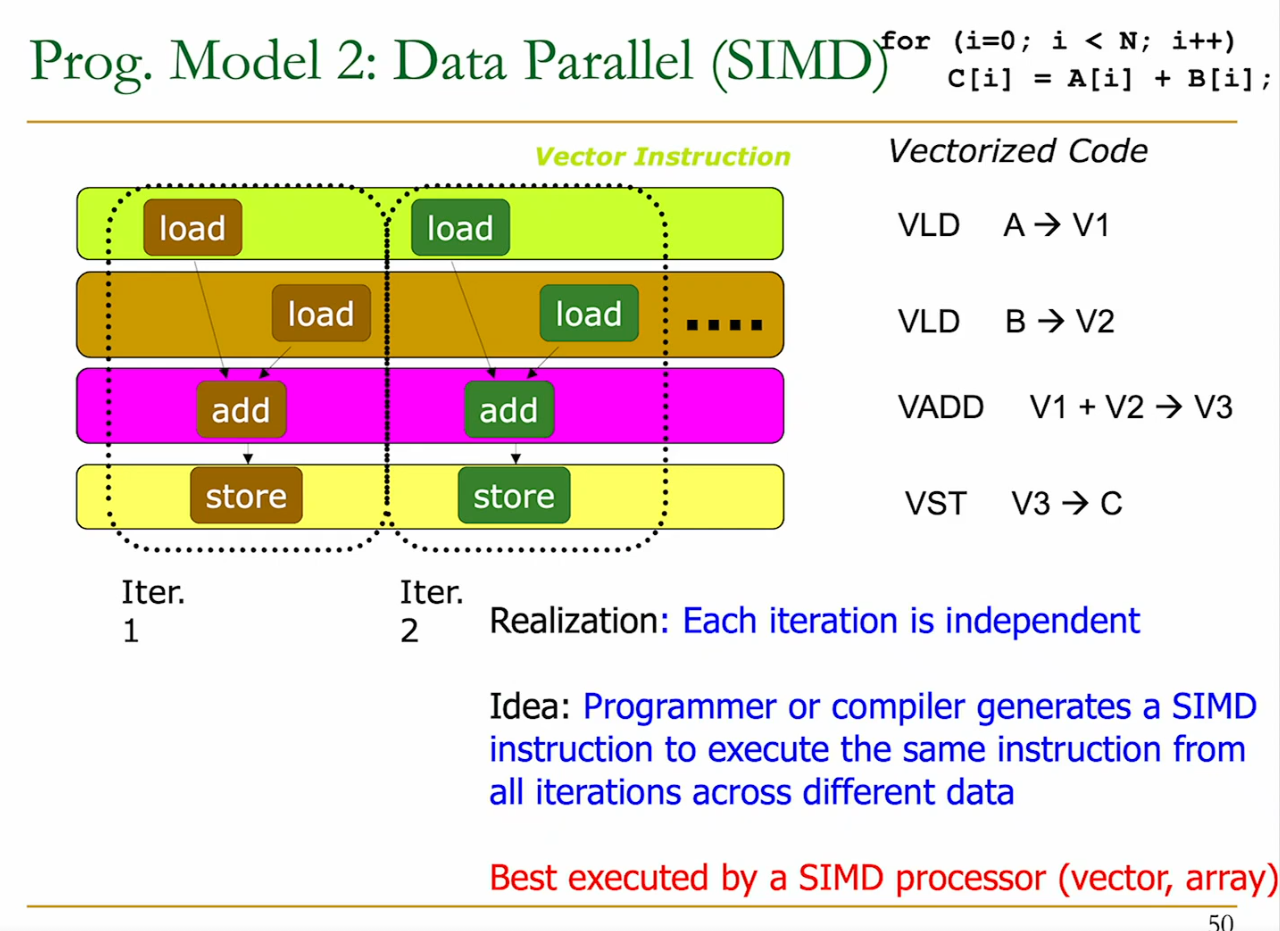
the programmer manually finds the vectorization and uses the appropriate instructions.
3 - Multithreaded
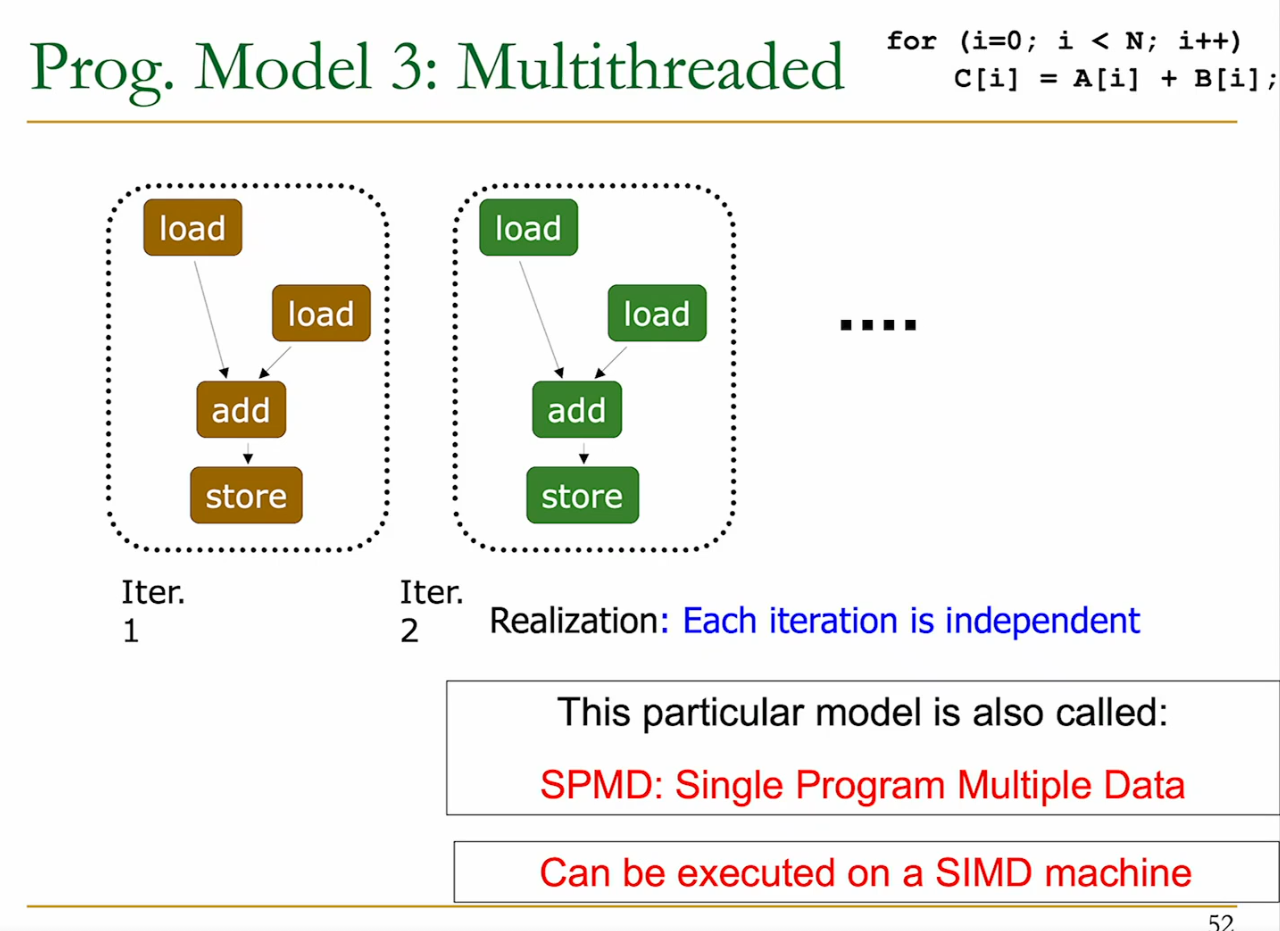
programmer or compiler generates a thread to execute each iteration. Each thread does the same thing.
Nvidia calls this SIMT (Single instructions, multiple threads).
→ Easier to reason about, no need to extract vector instructions.
21.1 GPU Architecture
21.1.0 SPMD (Same Program, Multiple Data)
Single procedure, multiple data
- this is a programming model, rather than computer organization
Procedures can synchronise at certain points in program → barriers
Multiple instruction streams execute same program
→ each program
- works on different data
- can execute a different control-flow path
21.1.1 Warps
It is programmed using threads → SPMD:
- Each thread executes the same code, but operates on a different piece of data
- each thread has it’s own context
- can be treated / restarted / executed independently
A set of threads executing the same instruction are dynamically grouped into a warp (wavefront) by the hardware
→ (kinda like OoO doing the hardwork in hardware rather than us thinking about it.)
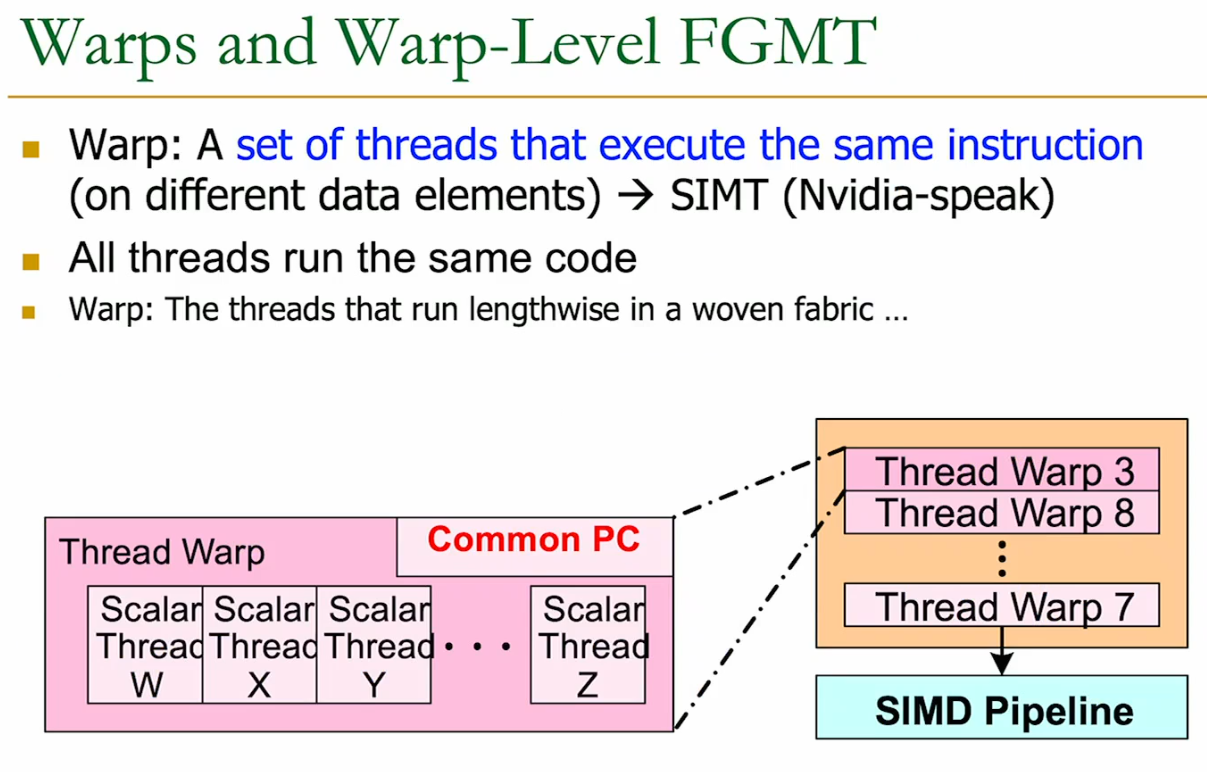
A Warp is essentially a set of threads grouped to perform a SIMD operation (formed by hardware, not by the programmer).
Example Code that runs for 32k iterations.
- We group 32 threads into a warp.
- Then we have in total 1k warps running in parallel.
Within a warp → running in lockstep iterations. So warp 0 at PC X + 3 is 32 threads all doing the same thing = store (iterations 0-31 of the loop).
The different warps may be at different positions in the instruction stream though.
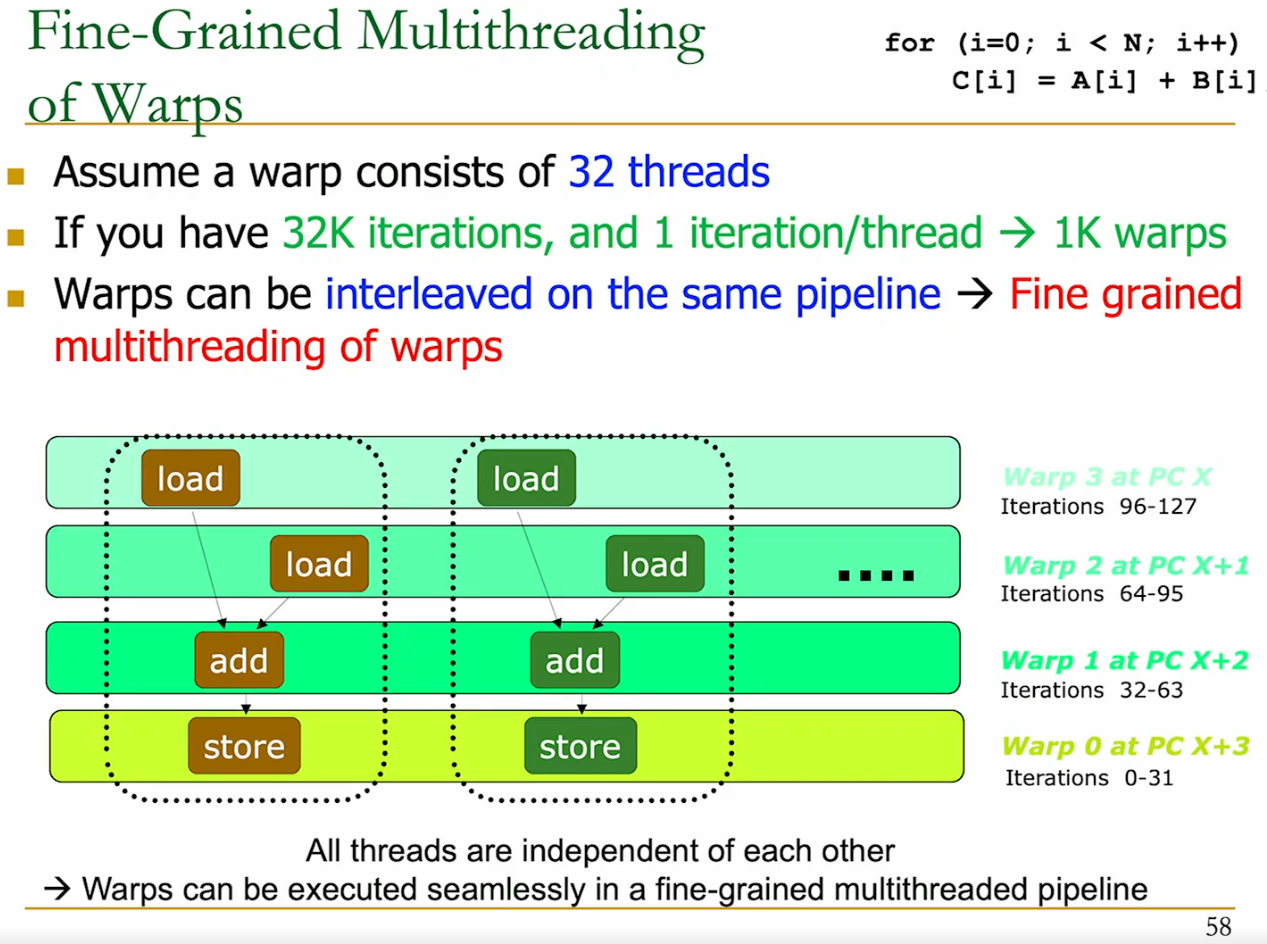
From the warp number and the program counter offset, we can figure out which iteration it is currently running.
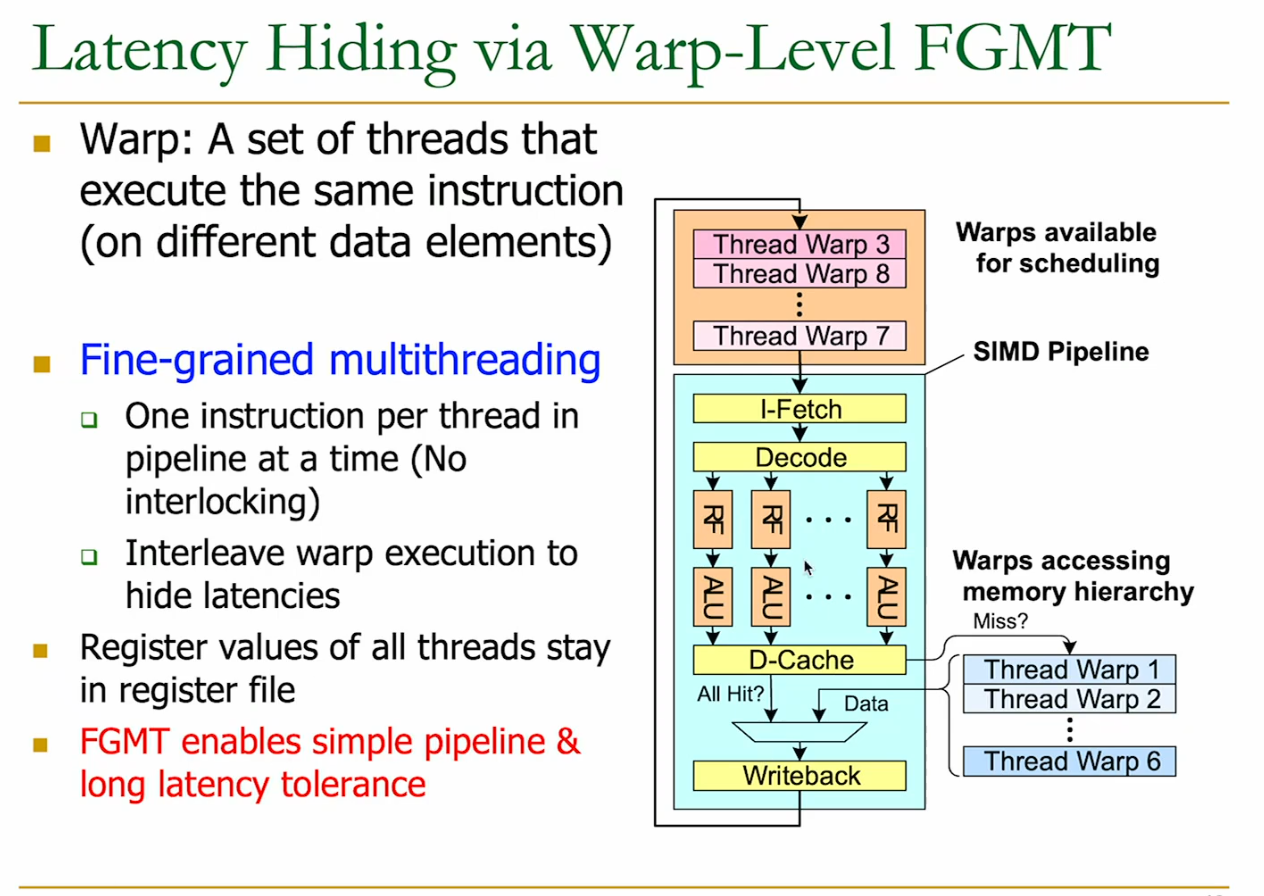
Similar to Fine Grained Multithreading (FMT):
- warp scheduler picks a ready warp each cycle
- prevents loads stalling or hazards for example
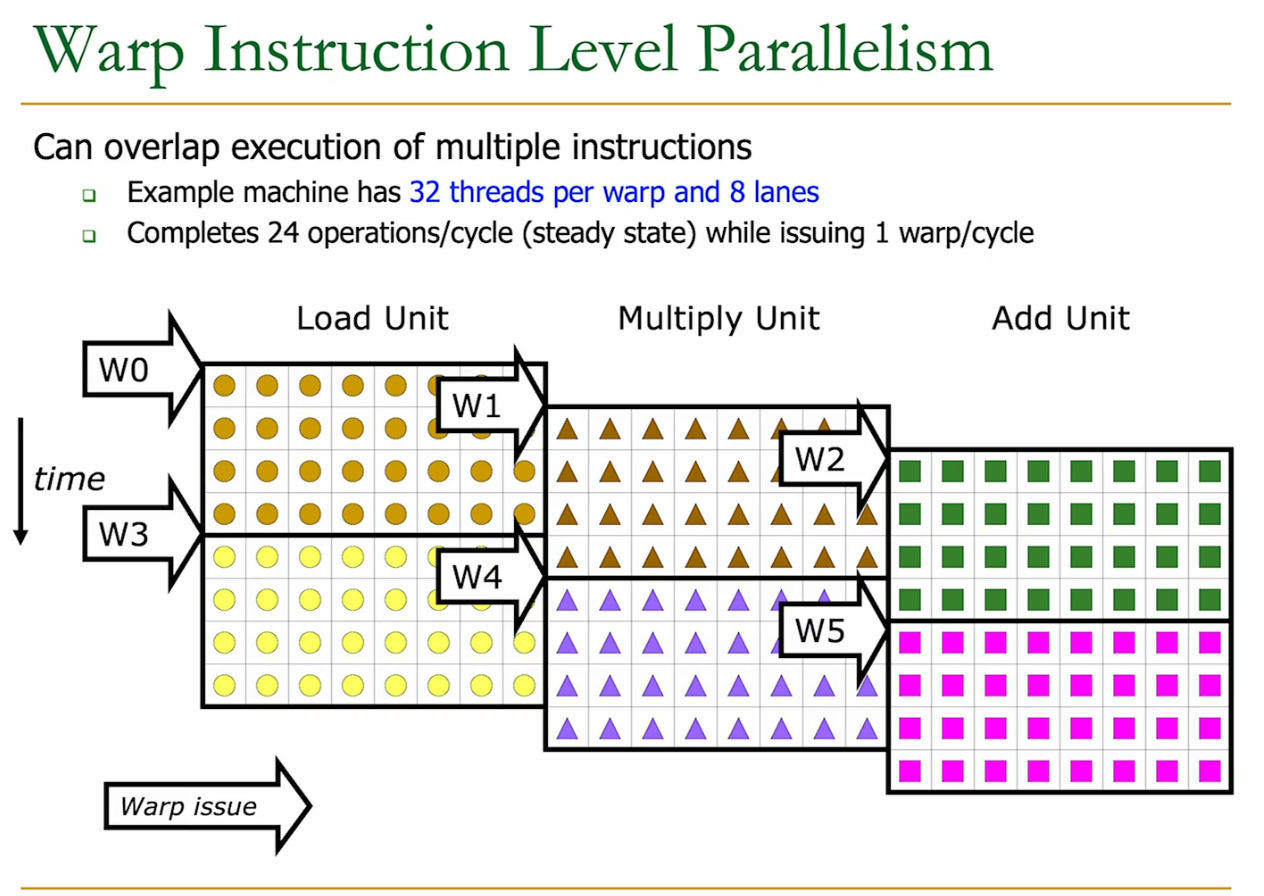
ILP in a warp.
21.1.2 SIMD vs. SIMT

Warp cannot be controlled by the programmer → all done in hardware.
21.2 Warp Execution

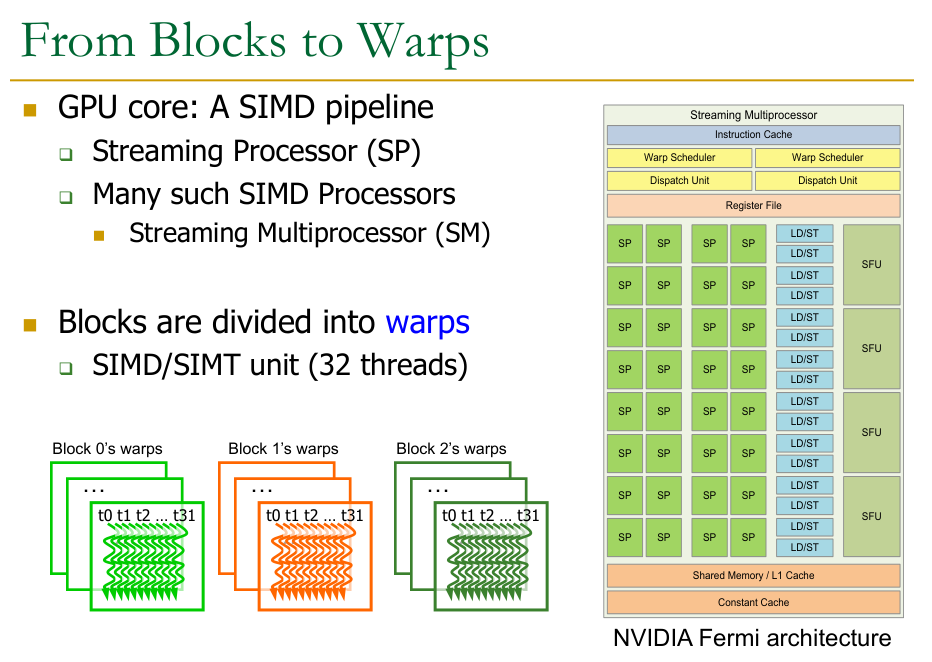
Threads are organized into blocks by the programmer, and the GPU hardware divides these blocks into warps. Each warp is then scheduled onto an SM.
The same instruction in different threads use thread id to index and access different data elements.
Example CUDA code, using threadIds.
No reference to warps → only done in hardware.
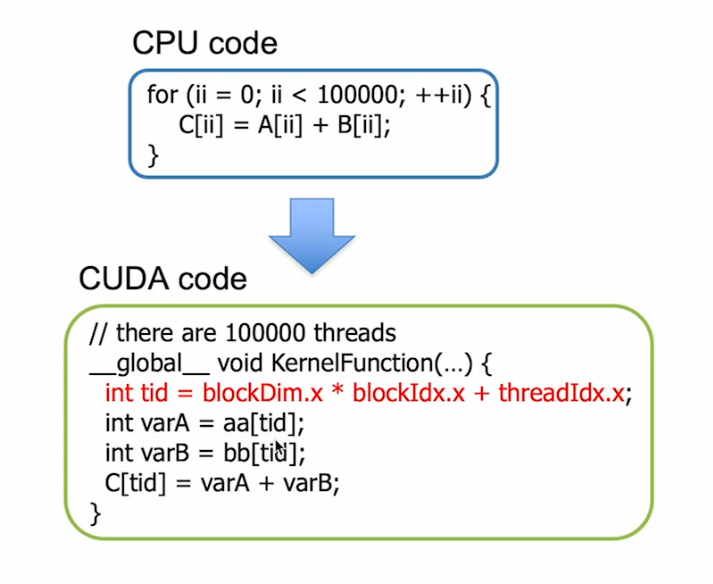
In CUDA you write a kernel function → defines what one thread does. Then you launch it across a whole grid of threads at once:
kernelFunction<<<numBlocks, threadsPerBlock>>>(C, A, B, N);
A block then has
- shared memory (scratchpad)
- barriers (with
__syncthreads) - must be independent
They are assigned to exactly one SM and run there from start to finish.
It is dynamically grouped into warps, and run by the warp scheduler.
21.2 Warp-based SIMD vs. traditional SIMD
Traditional SIMD contains a single thread:
- sequential instruction execution
- lock-step operations
- Programming model is SIMD (no extra threads) → need to know vector length
- ISA contains vector/SIMD instructions
Warp-based SIMD
- multiple scalar threads executing in SIMD manner
- same instruction by all threads, lock-step
- each thread can be treated individually
- i.e. placed in different warp
- programmer does not need to know vector length
- enables multithreading and flexible dynamic grouping of threads
- ISA is scalar → SIMD formed dynamically in hardware
→ The GPU is not programmed using SIMD instructions!

21.2.1 Warps and Branching
Initially the threads are all grouped into warps → statically, into 32 threads per warp.
This does not change after block is created, fixed over the lifetime.
→ as branching happens, we partition a warp into “sub-warps”
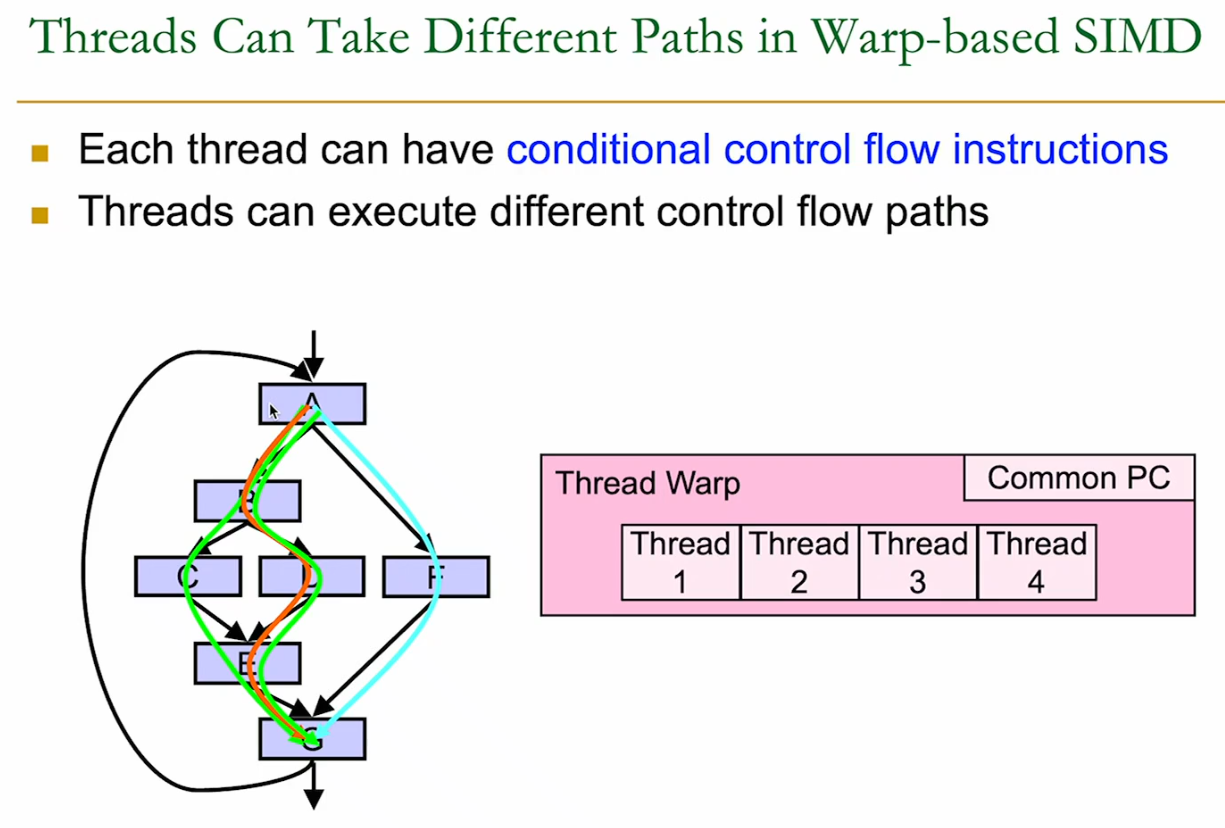
Example Control Flow
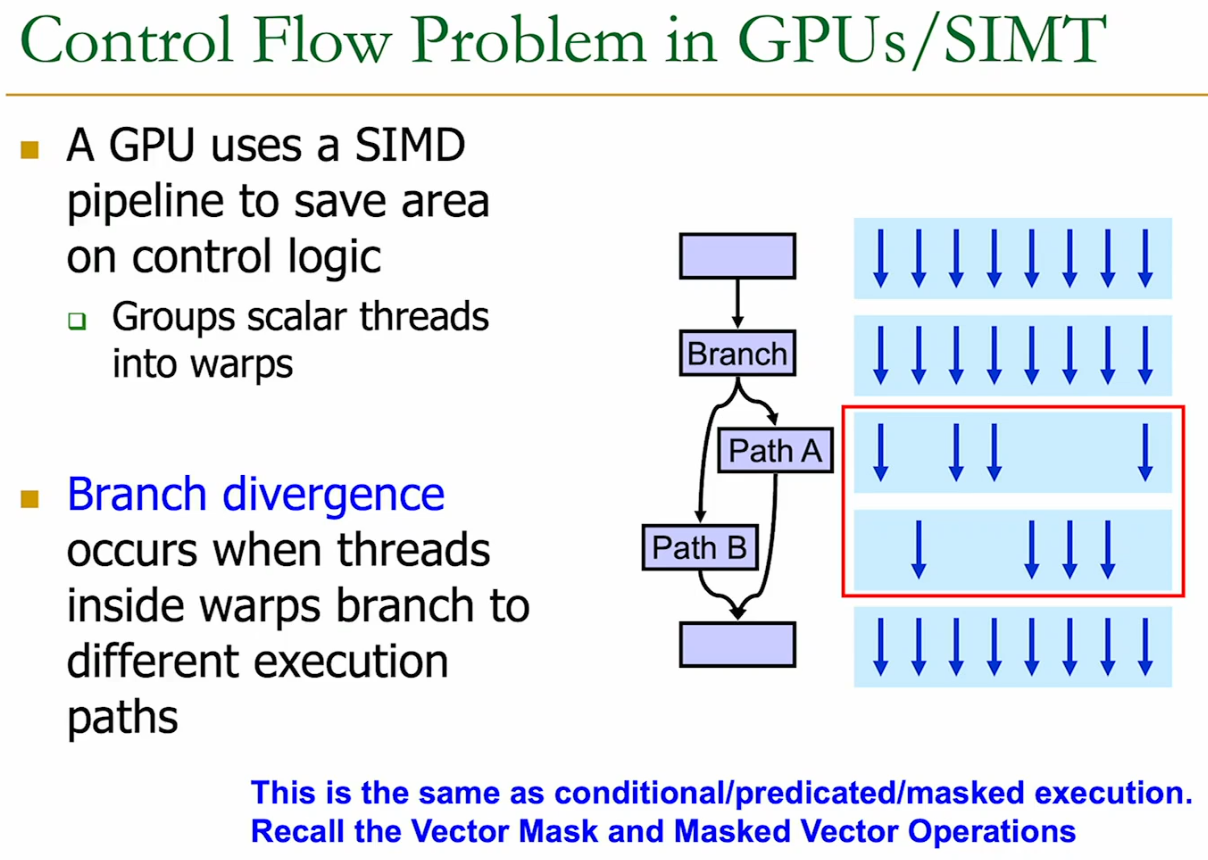
On a branch, some threads are turned off (masked), then the if and else branches are executed serially.
21.2.2 Dynamic Grouping into Warps
Note: This is a concept from academia → not actually implemented in Nvidia GPUs.
Dynamic Warp Formation the more warps we look at, the higher the probability that we can merge them into one.
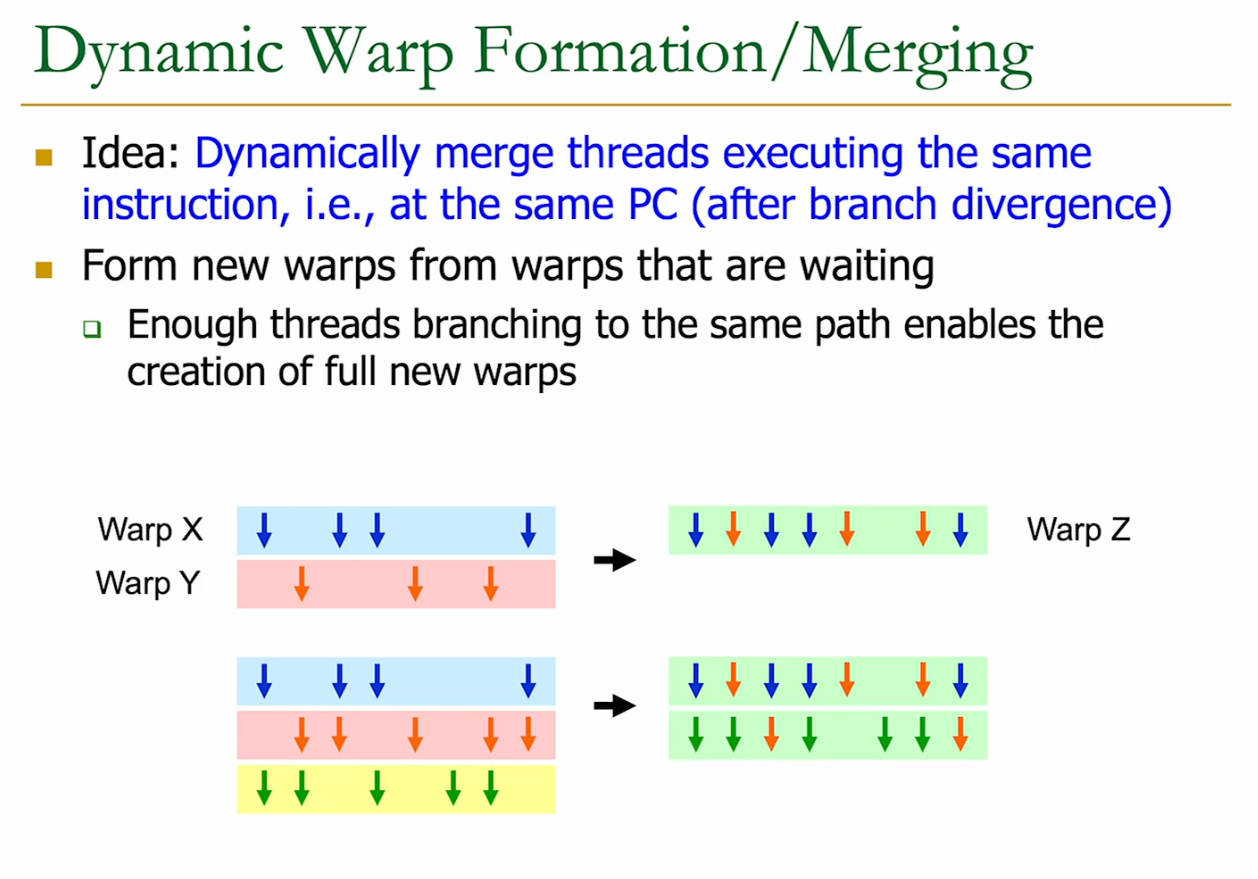
We look for different warps with threads that are branching to the same path.
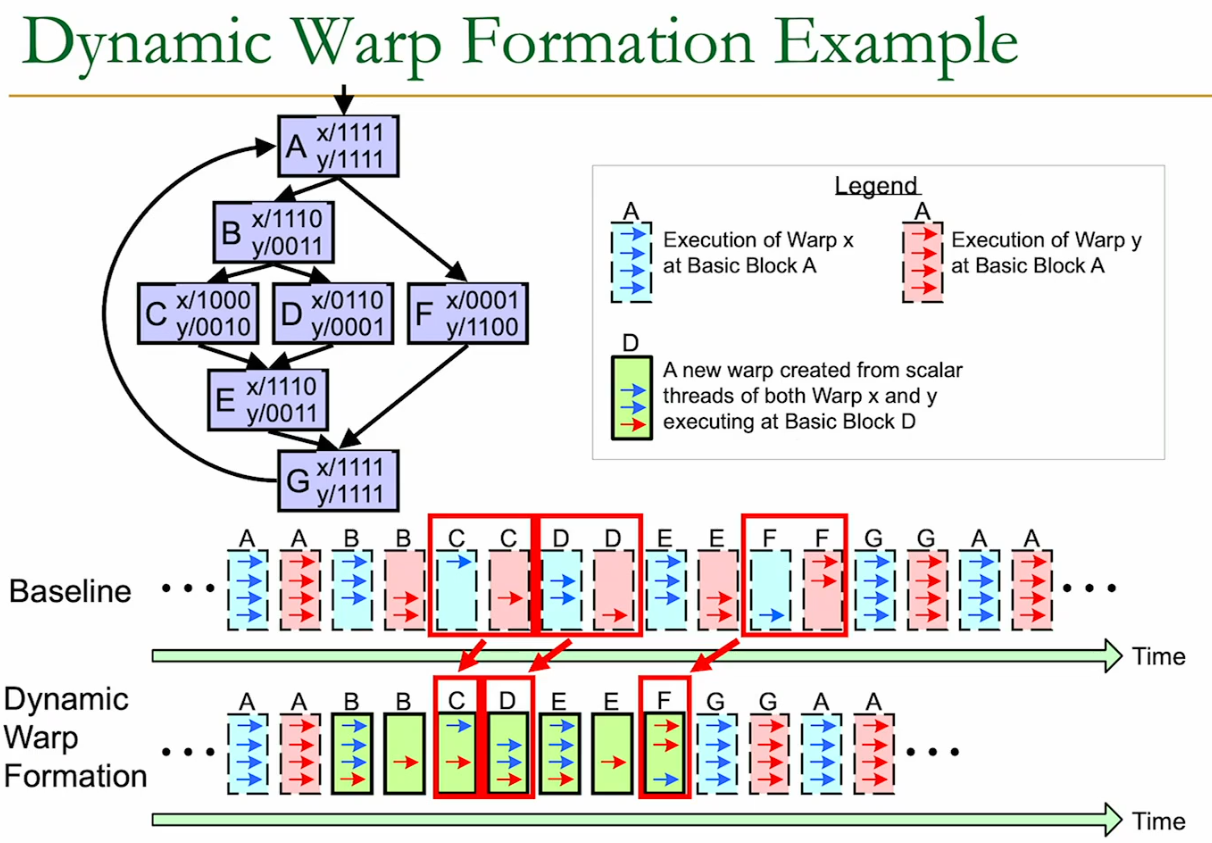
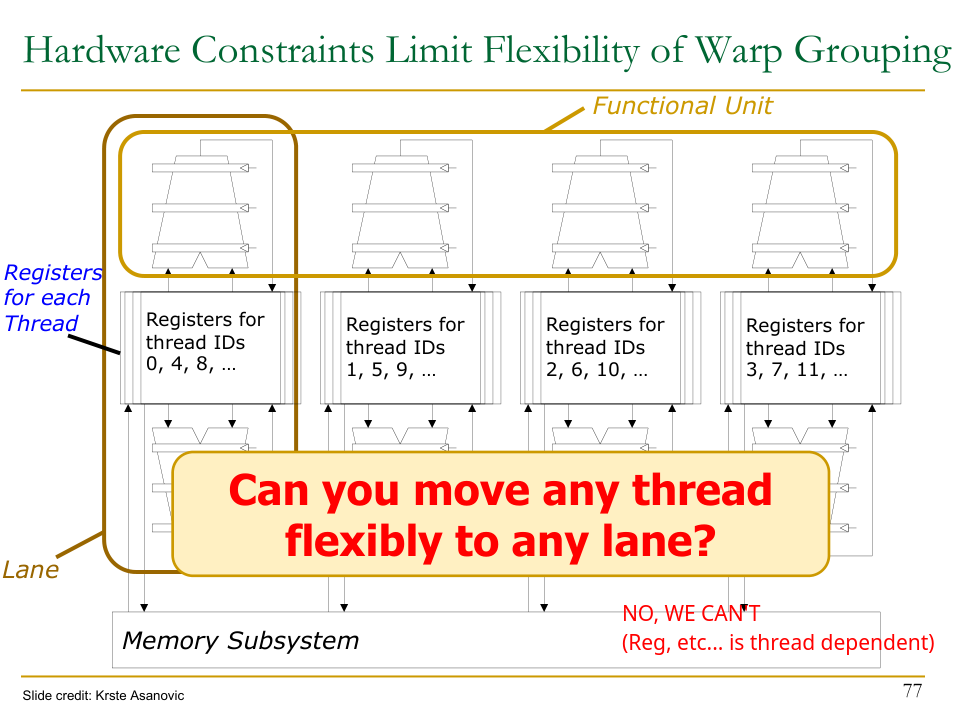
However, the flexibility of dynamically grouping the threads is constrained by hardware → physical mapping of thread registers to the SIMD lanes.
A thread is tied to a specific lane → not all threads can be in the same warp.