We will look at five different implementations of a Set, based on a List → using different locking patterns.
Granularity types:
- coarse-grained locking
- one global lock
- fine-grained locking
- one lock per item
- optimistic synchronization
- assume rare conflicts (use CAS to check for conflict, then retry)
- lazy synchronization
- delay or simplify cleanup work
- mark things as “deleted”
- Lock-free synchronization
- use atomic hardware primitives (like CAS) exclusively to manage concurrent access without any mutex locks.
- immune to deadlock and better performance under certain conditions
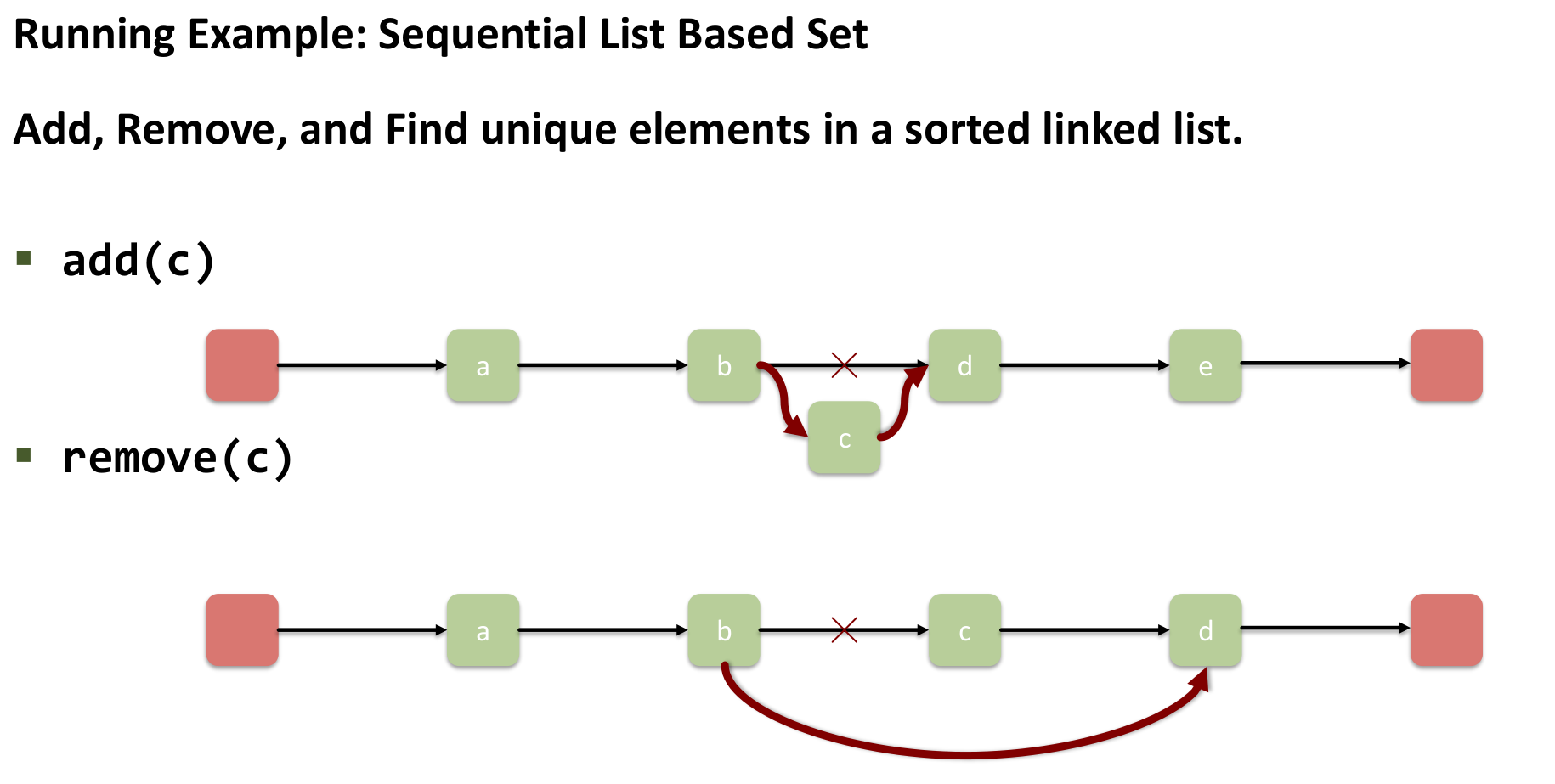
The List-based Set provides two operations:
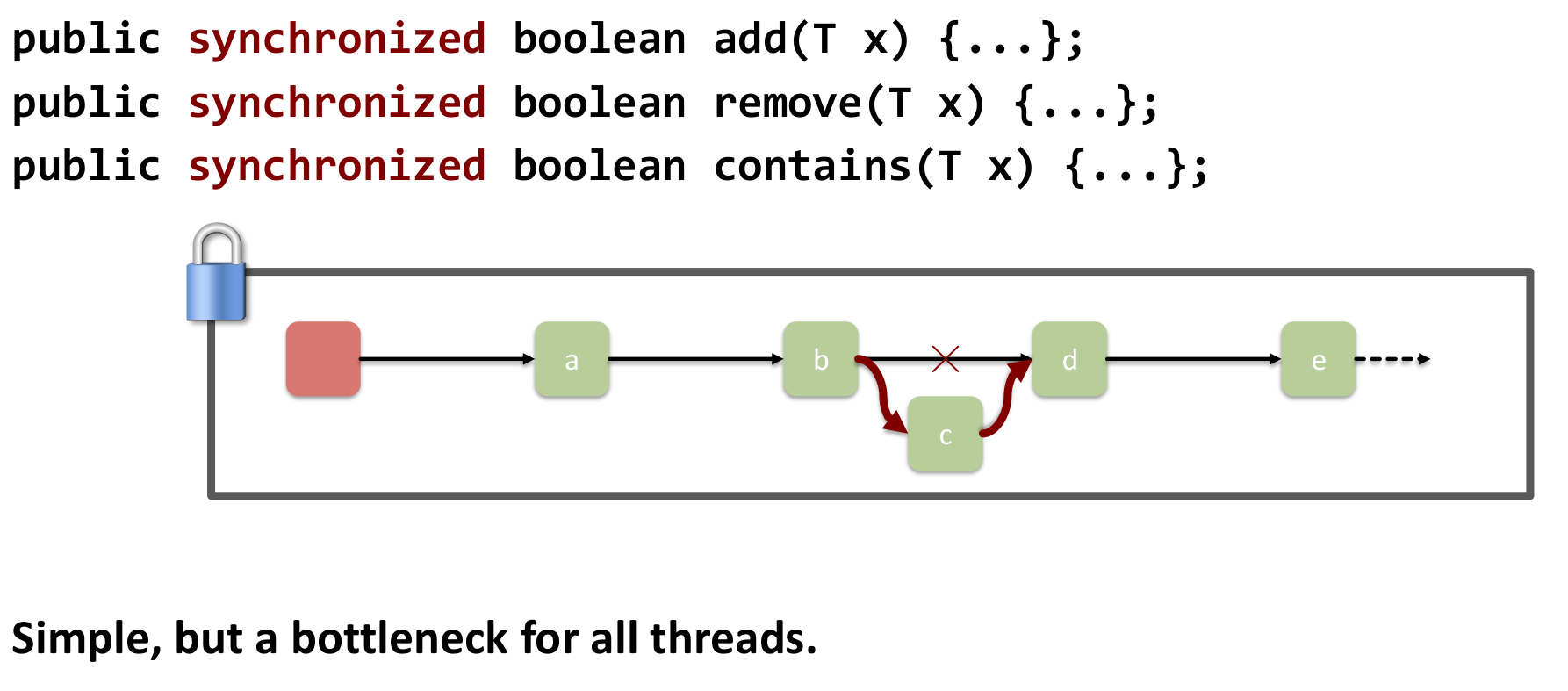
12.1 Coarse-Grained Locking
Coarse-grained locking would just synchronize add, remove, contains.
We have to traverse the list in for any op, thus very inefficient with a global lock!
12.2 Fine-Grained Locking
Fine-grained aims to split the object (list) into pieces (nodes) with separate locks, allowing concurrent operations on disjoint parts.
→ modifying element at start and removing one at the end doesn’t interfere so should be possible concurrently…
12.2.1 Naive Implementation
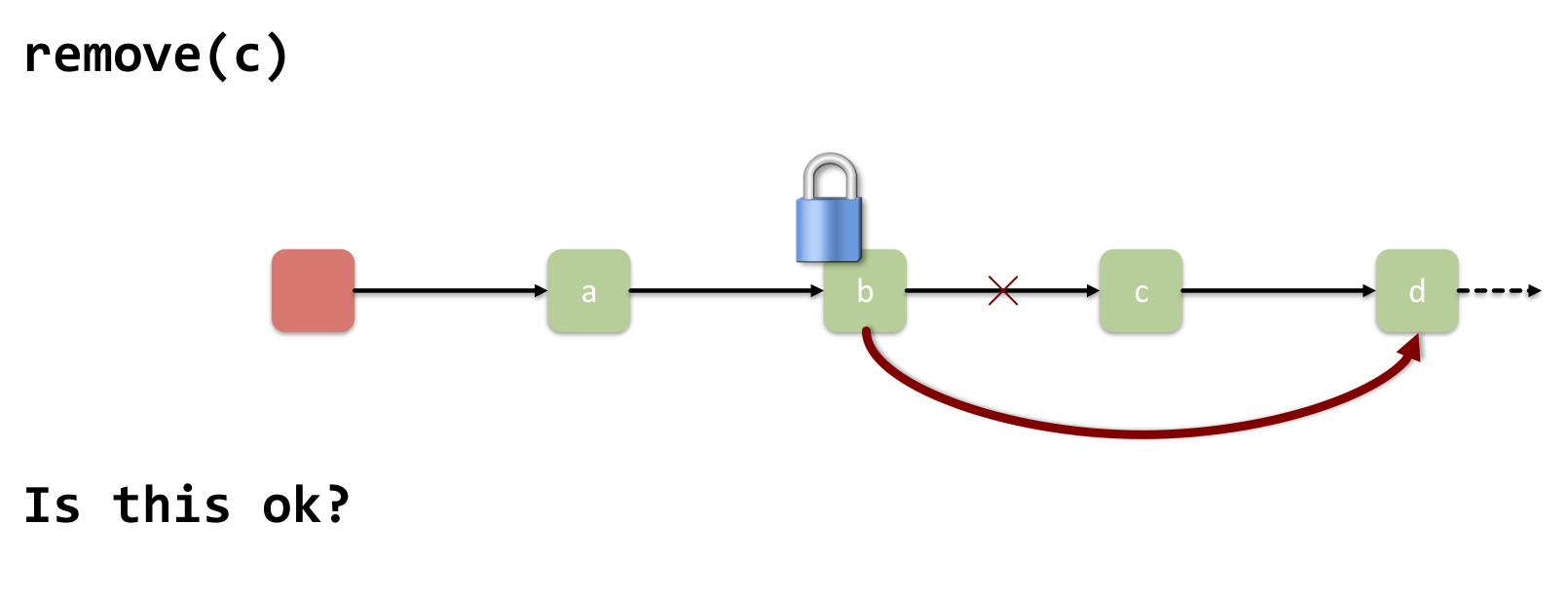
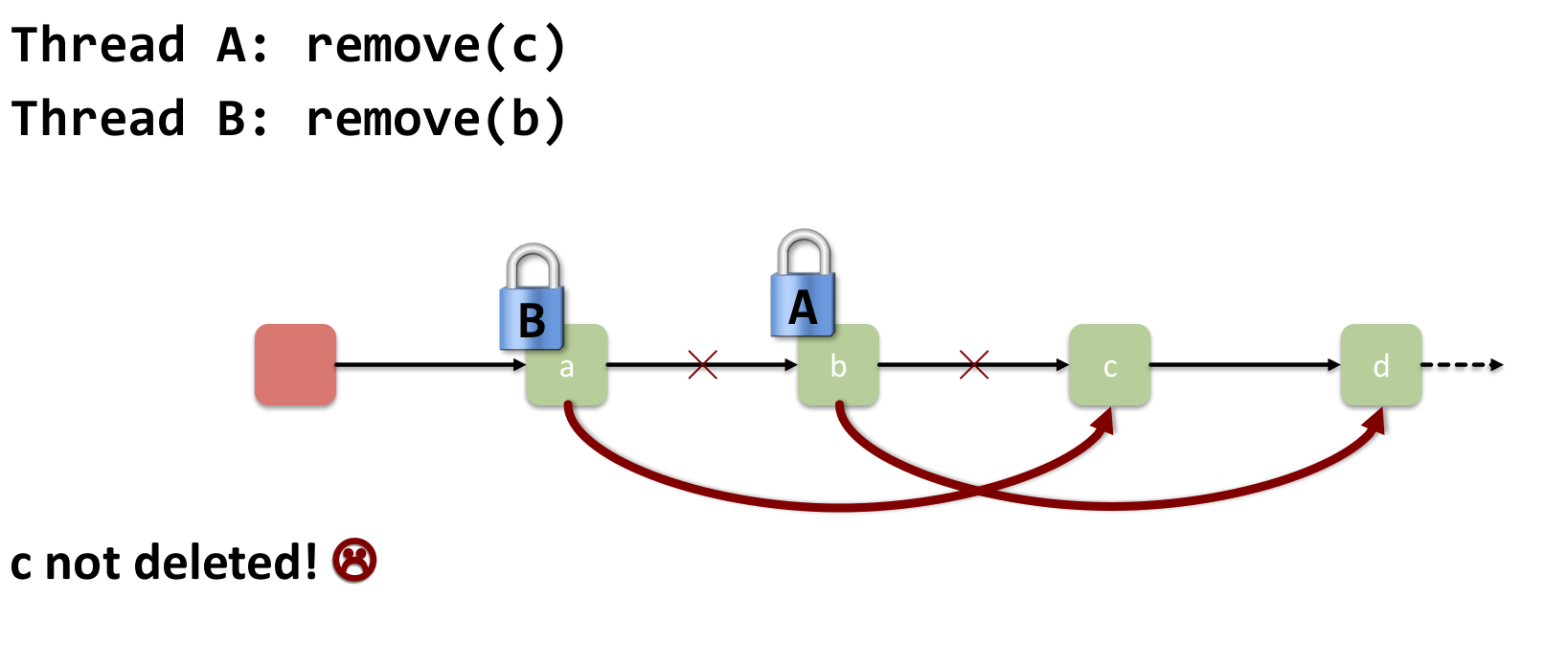
This collapses when we have conflicting operations:
12.2.2 Hand-over-Hand Locking (Lock Coupling)
Like Mogli/Tarzan in the jungle.
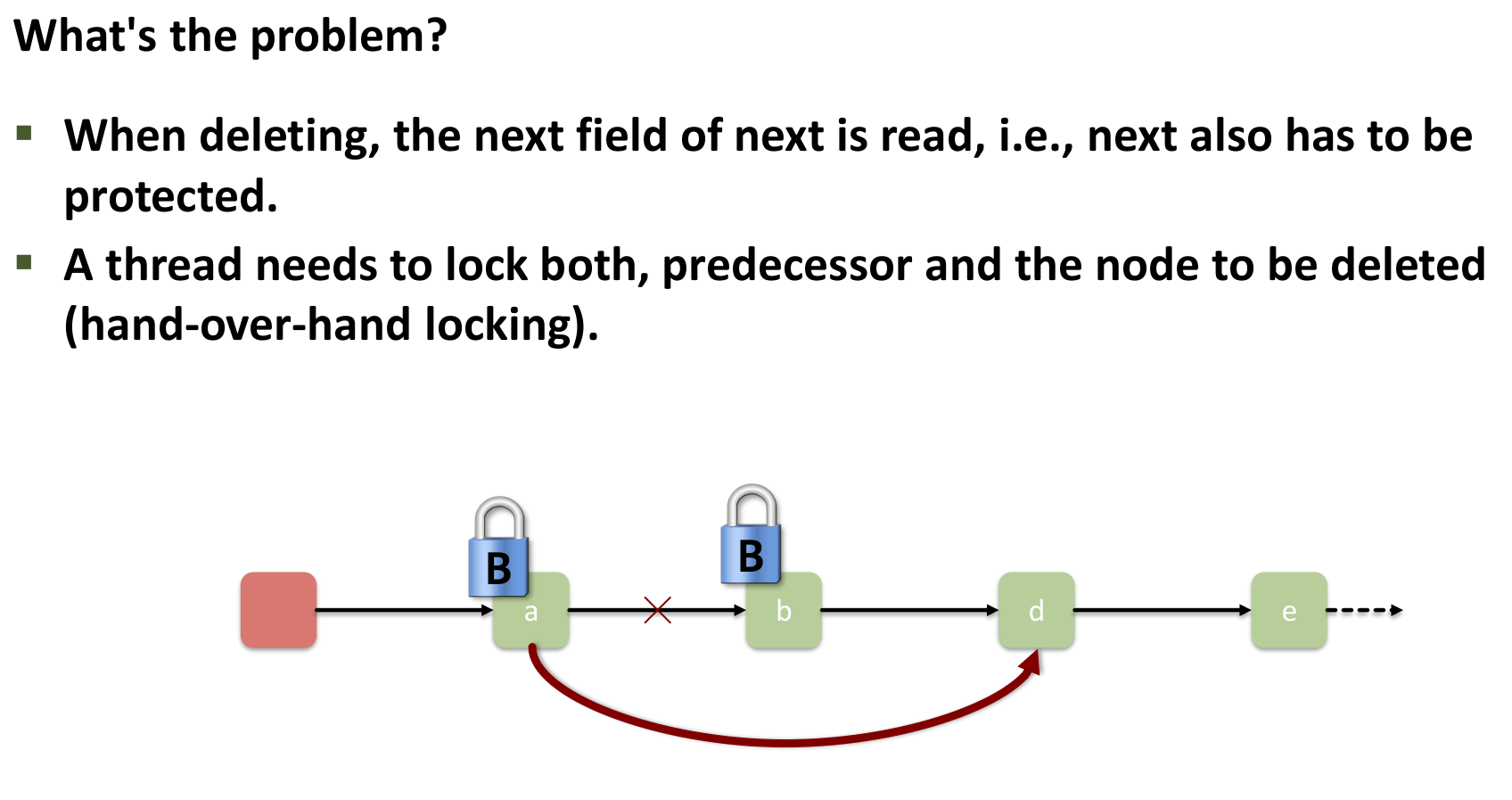
The Problem: Modifying the list structure requires coordinated, exclusive access to multiple adjacent nodes simultaneously.
- Removing c requires locking both b (to change b.next) and c (to read c.next).
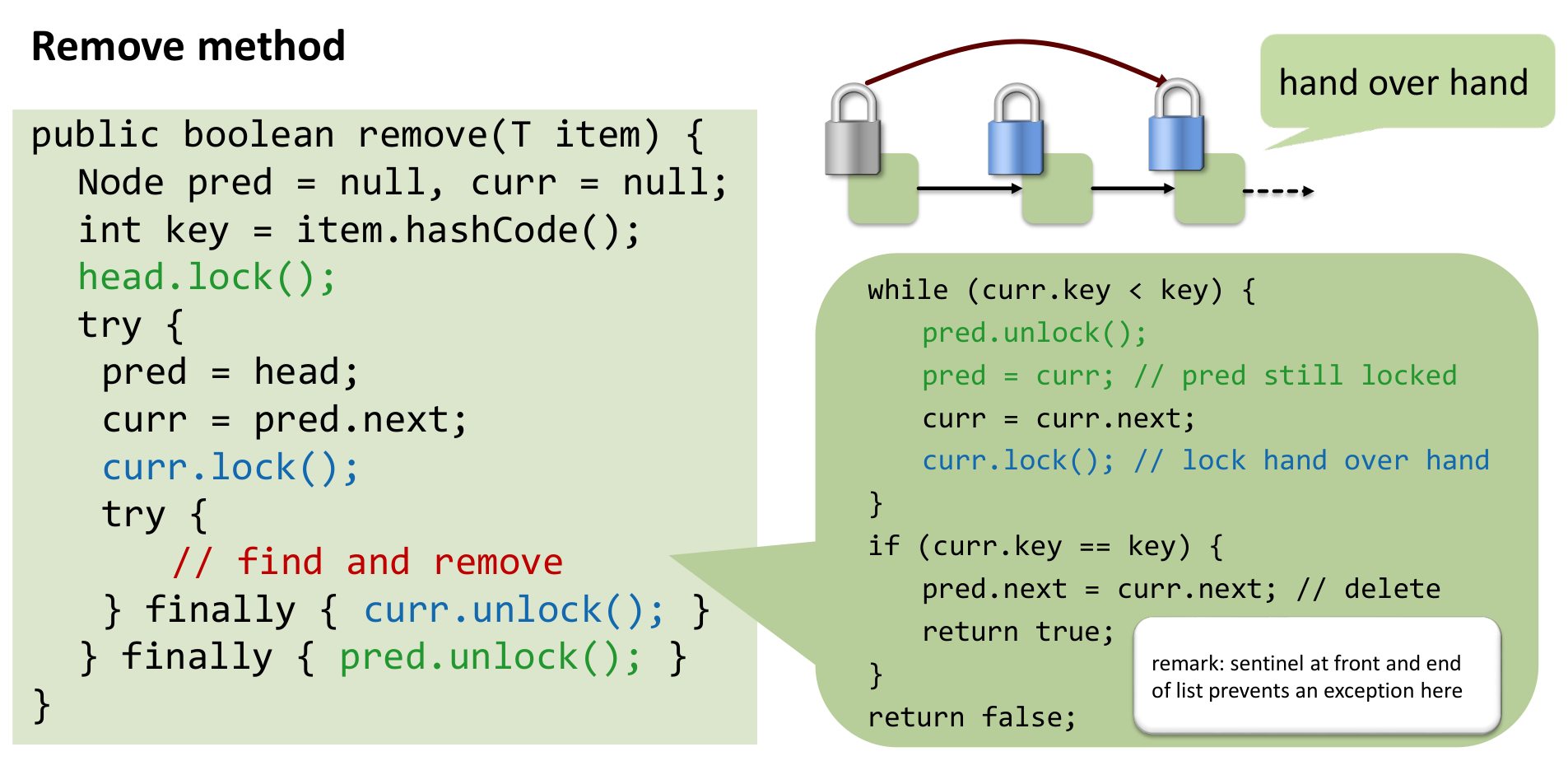
Fix? lock coupling:
- To traverse, always hold the lock on the current node you are examining.
- To move from
currtonext:- Lock
next(curr.next.lock()). - Unlock
curr(curr.unlock()).
- Lock
- To perform an operation (like delete) involving
predandcurr:- Traverse until
predandcurrare the nodes you need. - You will arrive holding the lock on
pred. - Lock
curr. - Now you hold locks on both
predandcurr. Perform the modification (e.g.,pred.next = curr.next). - Unlock
curr. - Unlock
pred.
- Traverse until
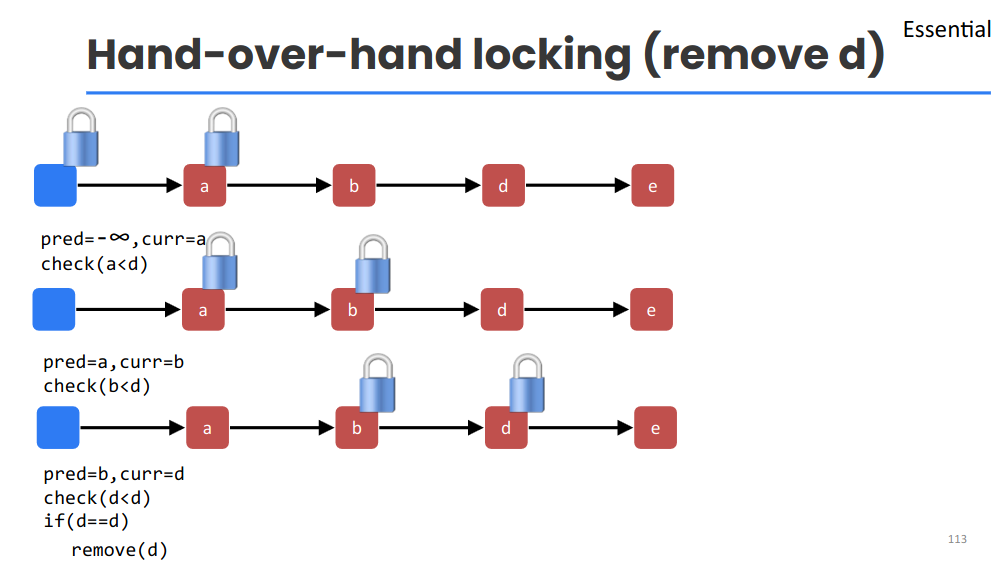
Why no deadlock?
All locks are acquired in the same order → traversal order of the list.
Cons of this:
- lots of acquire and release → overhead
- threads accessing disjoint parts can still block each other!!
- they need to “pass by each other”, which is not possible
- first thread sets tempo for all the ones after
- kein überholen basically
12.3 Optimistic Locking
Idea: find nodes without locking (i.e. find the pointers)
- check that everything is ok
Perform the operation in stages:
- Find Nodes (Lock-Free): Traverse the list without acquiring any locks to find the relevant nodes
- Lock Nodes: Once the target nodes are found, acquire locks only on those specific nodes.
- Validate: After acquiring locks, check if the situation is still valid.
- Did another thread modify the list structure (e.g., delete
predorcurr, insert between them) after stage 1 but before we acquired the locks in stage 2?
- Did another thread modify the list structure (e.g., delete
- Perform Operation: If validation succeeds, perform the actual modification (e.g., update pointers).
- Unlock: Release the locks. If validation fails, release locks and retry (or signal failure

Validation Summary
The
validate(pred, curr)method needs to lockpredandcurr:
- check if
predis still reachable fromhead- check if
curris still the immediate successor ofpred(pred.next == curr)
Implicitly check if pred/curr not marked deleted (relevant for lazy lists)
Proof:
remove(c)if validation passes while holding locks onbandc:- no other thread can be deleting
borcnor inserting between them
- no other thread can be deleting
remove(c)wherecnot found → we can safely return false if validation passes while holding bothbandd- no other thread could have inserted between them.
12.3.1 Example add(c)
- Traverse without locks, finding that
cshould go betweenbandd. - Lock
bandd. - Validate: Is
bstill reachable? Isdstill the successor ofb? - If valid, set
c.next = d,b.next = c. - Unlock
bandd.
Failure 1: (Deletion)
- the prev. node to the one we want to delete could be “detached from the list”
- then our deletion changes nothing relevant → node outside of list is not traversed anymore
- out operation was made moot
Validate: have to check pred still reachable
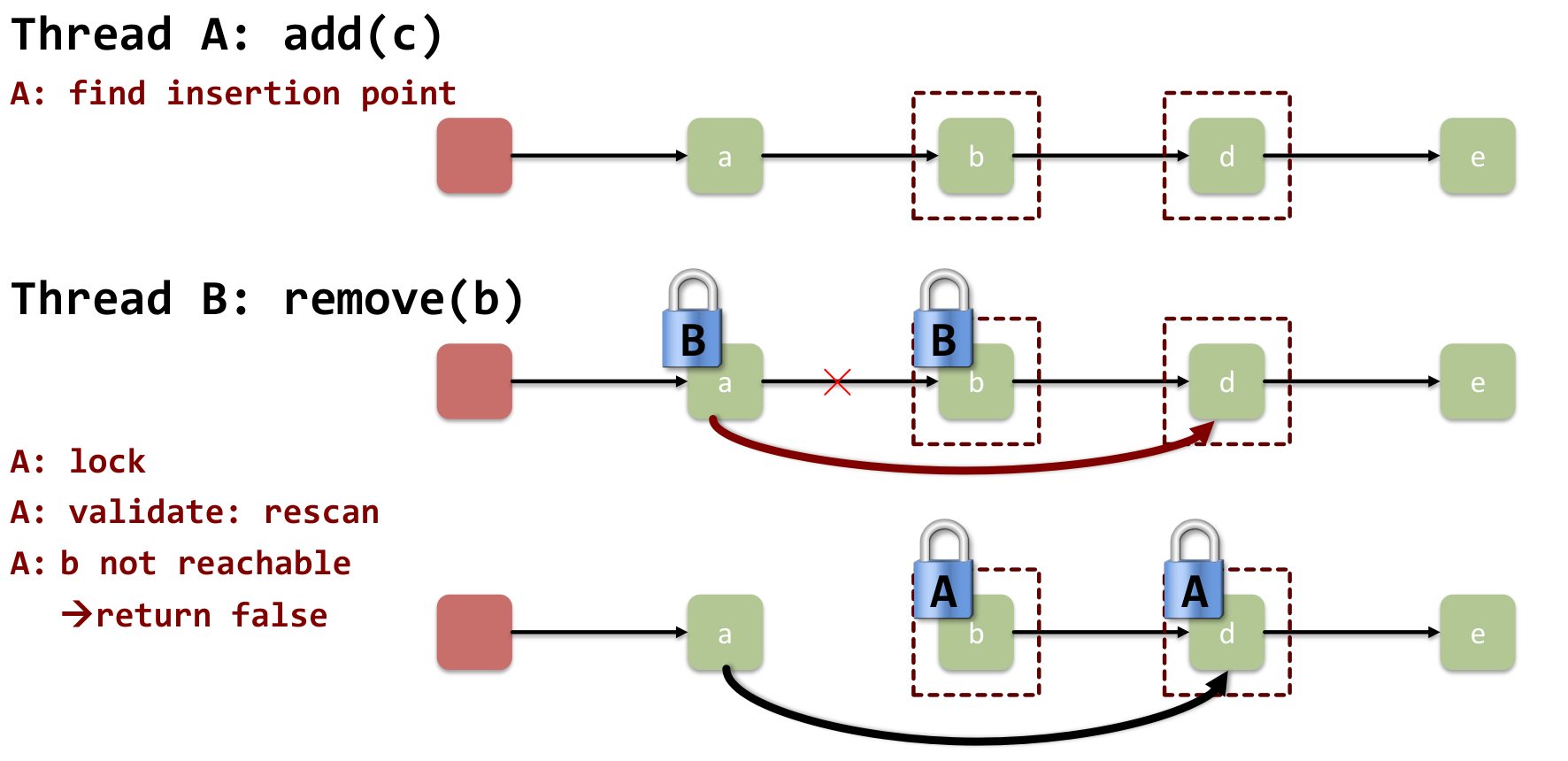
Failure 2: (Insertion)
- another thread could have arrived and inserted a new node in between the ones we wanted to insert into
- then we validate → fails
- we have to redo everything (rescan)
Validate: have to check pred.next == succ
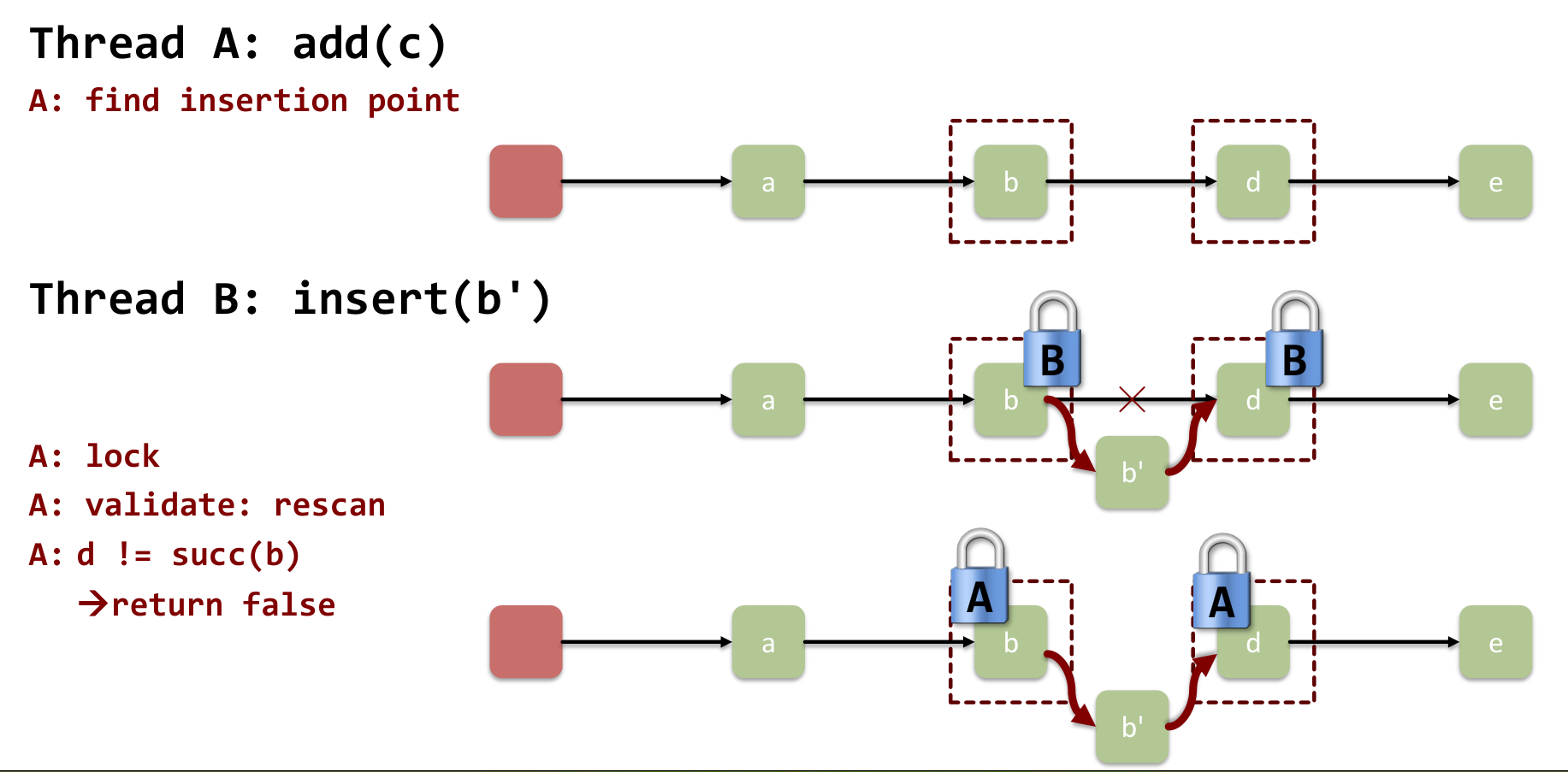
Trade-Offs:
Pro
- no contention on traversals
- wait-free traversals even → completes in a finite number of its own steps regardless of other threads speeds or pausing
- fewer lock acquisitions
Con - double traversal (scan, lock, validate-scan, modify)
contains()needs locks → if we don’t validate, we might return true for a node currently being deleted- not starvation-free → threads might repeatedly fail validation due to high contention
Note:
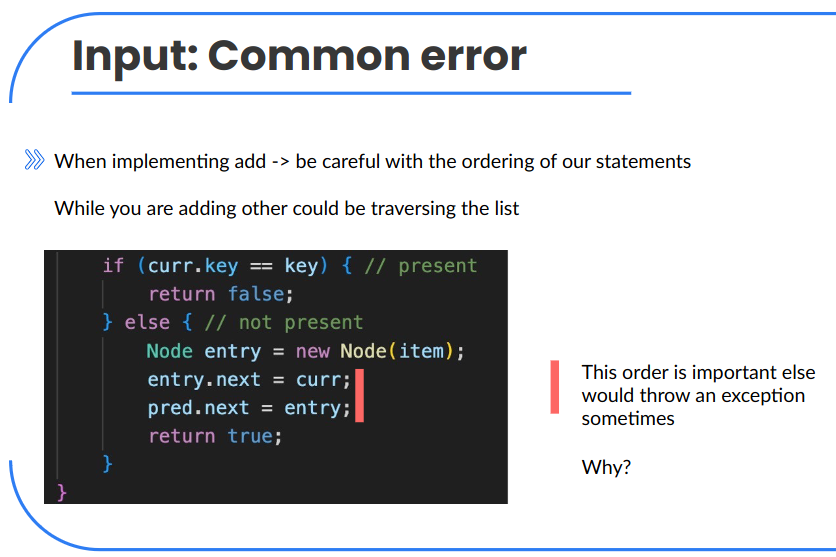
if we do it in the other order:
- another thread traversing here would find a dead-end in
entry.
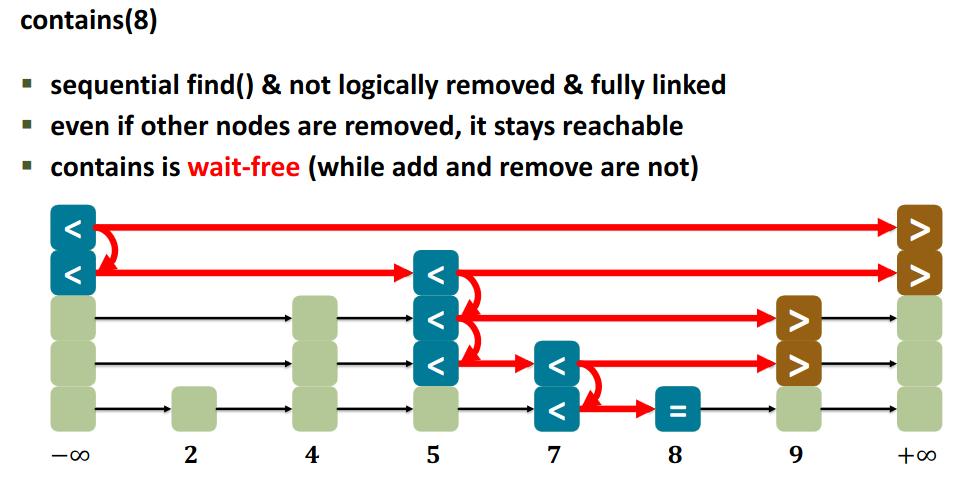
12.4 Lazy Synchronization
The Lazy List Approach is similar to optimistic list but:
- scan only once
contains()never locks A simple scan is sufficient.
How? Removing nodes causes trouble →
- uses deletion-markers → remove first marks the node as “logically deleted”
- Physical Deletion (Lazy) is done later
- potentially by the same
removeoperation or by subsequent traversals
- potentially by the same
Key Invariant: Every unmarked node in the list must always be reachable from the head. contains only returns true for unmarked nodes.
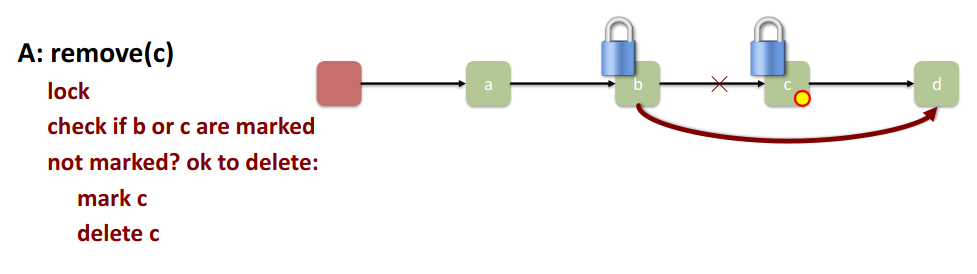
Implementation:

→ first logically remove → then physically remove!
Validation is now slightly modified:
- check if
predis reachable (by checking if it’s marked) and points to curr - check that
curris not already marked as deleted.
Wait-free contains implementation:

contains is wait-free:
- does not lock
- does not have a “retry-loop”
- no “stranding” → only logical deletion: the next pointer still points forward, thus we can always advance in the list
for themarkedbit, we can use avolatilevariable for mutex - if we didn’t race condition as we don’t acquire the lock on that node
- we do not have to use
AtomicMarkableReference→ just need to have latest value as guaranteed by volatile- in a lock-free list, we do need an
AtomicMarkableReference, because removes aren’t serialised by locks.- → race
- in a lock-free list, we do need an
12.5 Skip Lists
Collection of elements (without duplicates), same add/remove/find algorithms.
→ many calls to find and fewer to add and much fewer to remove
We use a las-vegas style randomised algorithm.
- will always find the element (or insert/remove)
- but the runtime is random
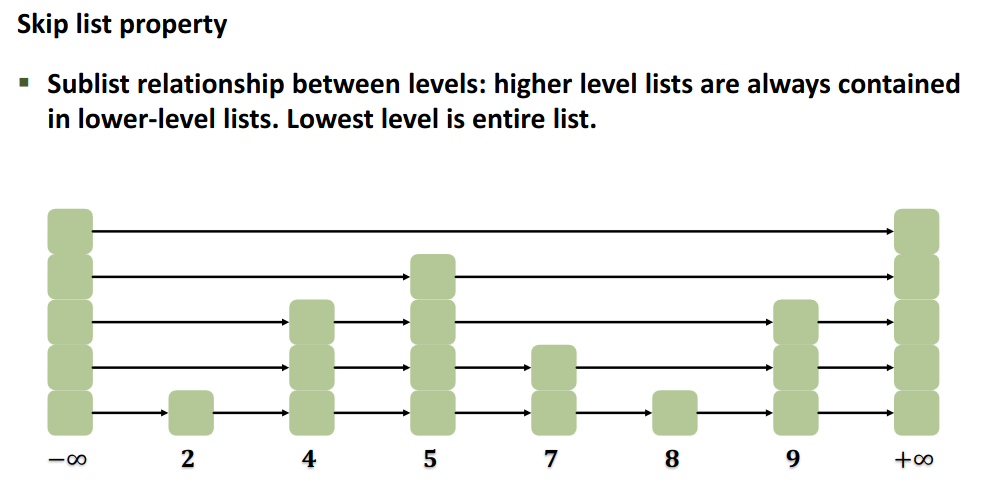
It’s a sorted multi-level list.
- the node “height” is probabilistic
- no rebalancing.
the list forms a kind of “binary-tree” probabilistically. Because it’s , we have on average this tree structure by the law of large numbers.
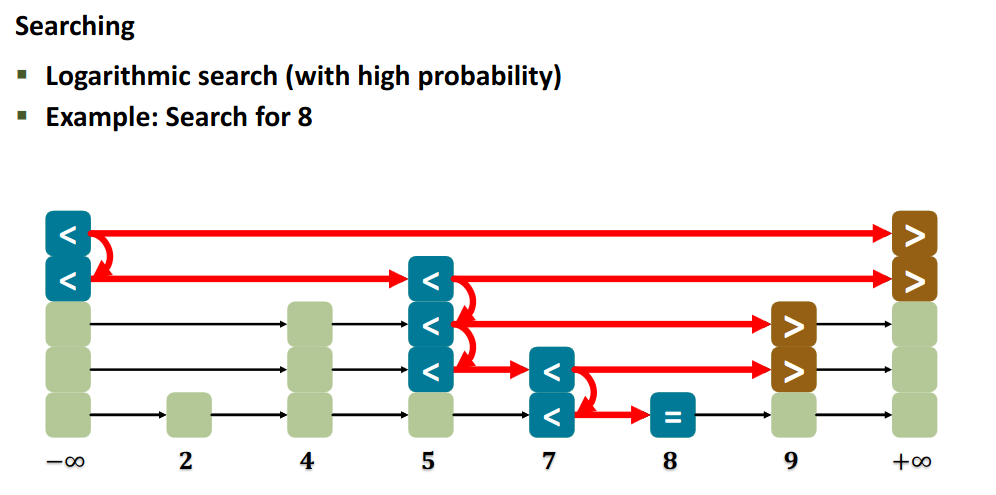
12.5.2 Sequential find
The “higher” you are, the “faster” you can traverse the list.
in practice, this looks like the following:
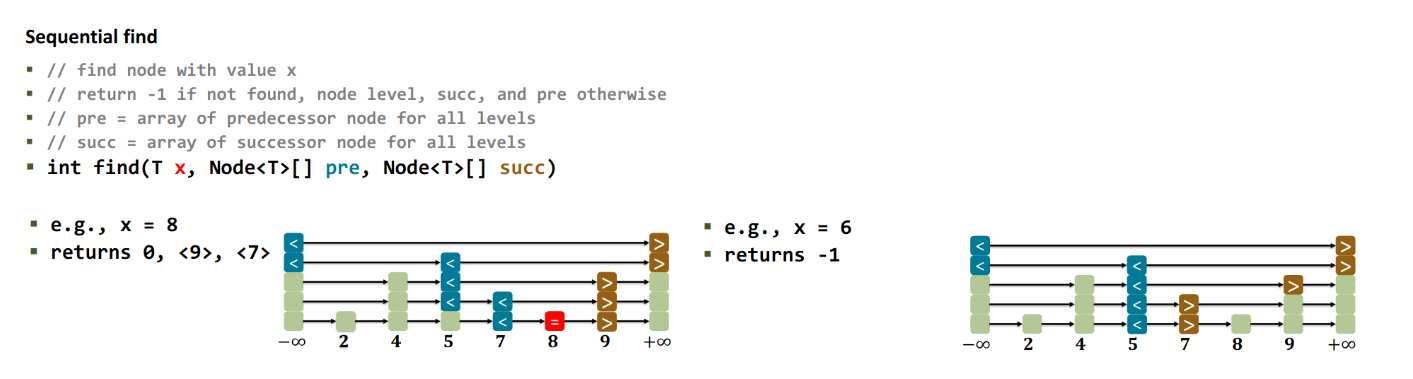
a node has multiple successor nodes → we check all of them. We proceed if than the target number.
- thanks to the list being sorted we can literally search like a “binary tree” left/right
12.5.2 Add
First, we determine the height of the current node → randomly choose a value uniformly.
Find predecessors?
- normal search - start at
heightof the element to be inserted - for each level:
- remember the last node you read before dropping down
- this gives for insertion of :
- all nodes
- with a pointer to an element
- these are the pointers we update
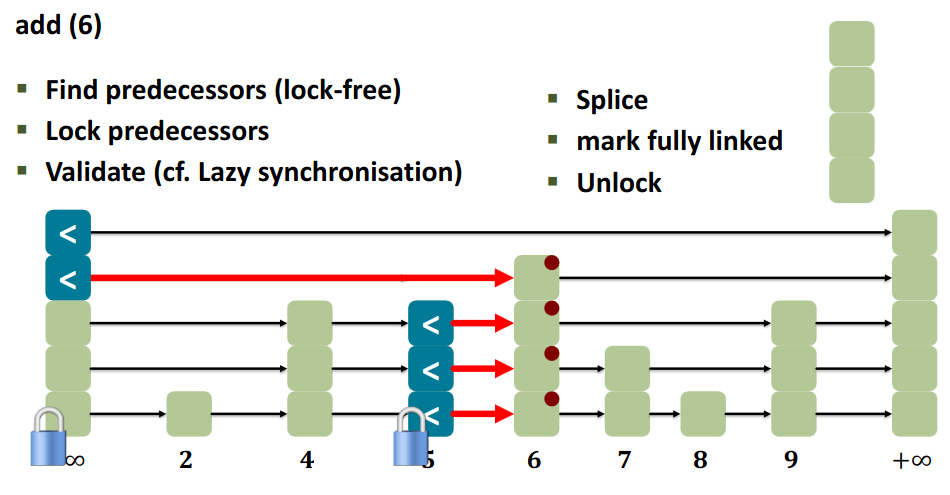
12.5.3 Remove
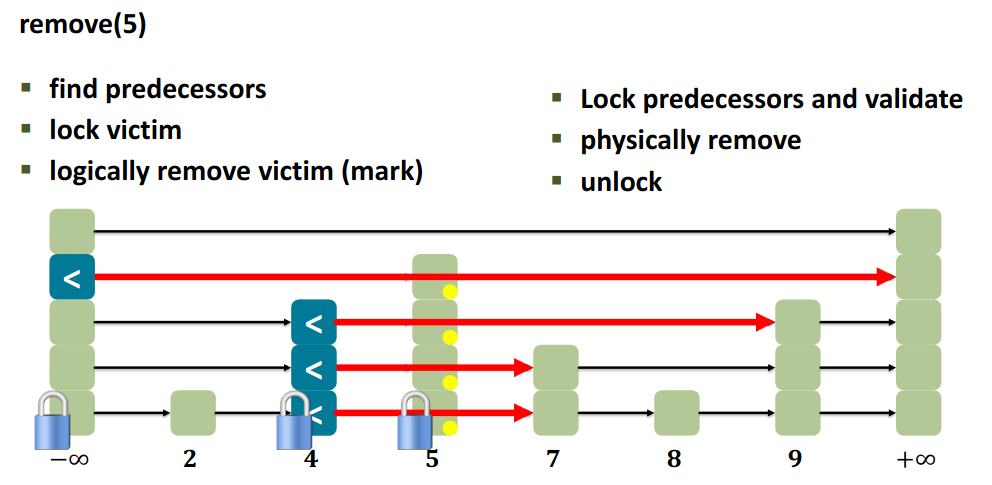
12.5.4 Contains (wait-free)