Recap We saw spinlocks vs. scheduled locks (wait, await)
Now we’ll do lock-free programming/datastructures
Spinlock problems:
- scheduling fairness → no FIFO behaviour
- computing resources wasted, performance degradation
- no notification mechanism
Locks with waiting problems: (semaphores, mutexes, monitors often implemented with such a lock)
- require OS support
- datastructures need to be protected against concurrent access
- we do this using spinlocks
- higher wakeup latency → scheduler involved
- if thread is delayed when in CS → all threads suffer
- what if thread dies in critical section
- prone to deadlocks
- locks cannot be used in interrupt handlers… (who handles the interrupt, in the interrupt handler)
13.1 Lock-Free Programming
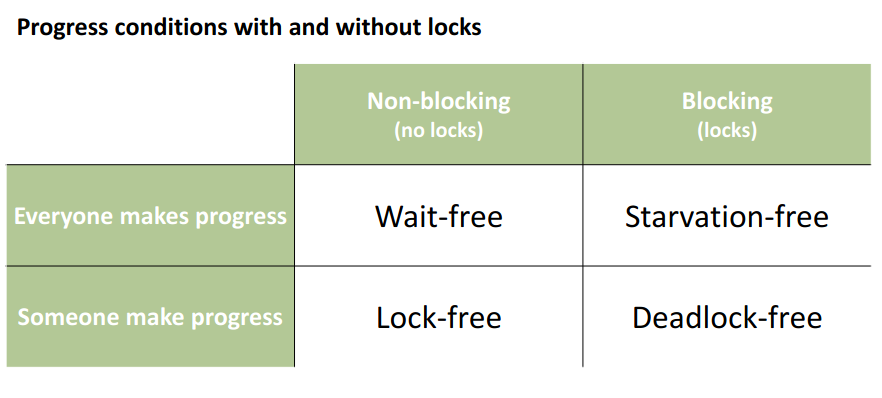
Lock-freedom: (= deadlock free) at least one thread always makes progress even if other threads run concurrently
- implies system-wide progress but not freedom from starvation
Wait-freedom: (=starvation-free) all threads eventually make progress - implies freedom from starvation
Wait-freedom (stronger!) lock-freedom

We can see the mapping between the concepts names in the two programming paradigm:
Non-blocking algorithms: locks/blocking → a thread can infinitely delay another thread
- non-blocking = failure/suspension of one thread cannot cause failure or suspension of another thread.

Note, in Java the following holds:
ReentrantLock
We can assume the
ReentrantLockis deadlock-free.
If we initialiseReentrantLock(true), then it’s also starvation-free, since the fairness-parameter is set totrue.
To program lock-free we use atomic operations.
CAS: can be implemented lock-free in hardware
- usually even wait-free (but depends on the java compiler for example)
13.1.2 Lock-Free Counter
Use CAS and redo until the counter was incremented by us.
public class CasCounter {
private AtomicInteger value;
public int getVal() {
return value.get();
}
public int inc() {
int v;
do {
v = value.get();
} while (!value.compareAndSet(v, v + 1));
return value;
}
}(usually in java we could just use .increment …)
This is a lock-free but not wait-free implementation → it doesn’t need to terminate in finite steps.
- that is because of the
whileloop - can be infinitely looping in worst-case
Positive result of CAS suggests that no other thread has written between .get and compareAndSet
- we read
a - other thread could have written
bin between - other thread modifies it again to
a - we
compareAndSet→ returns
ABA problem
13.1.3 DCAS
Double compare and swap
It allows performing a CAS on two memory locations at the same time.
Primitive (CPU operation) that can be used to implement software transactional memory (STM).
13.2 Lock-Free Stack
For a blocking stack, we can just use synchronized (global lock).
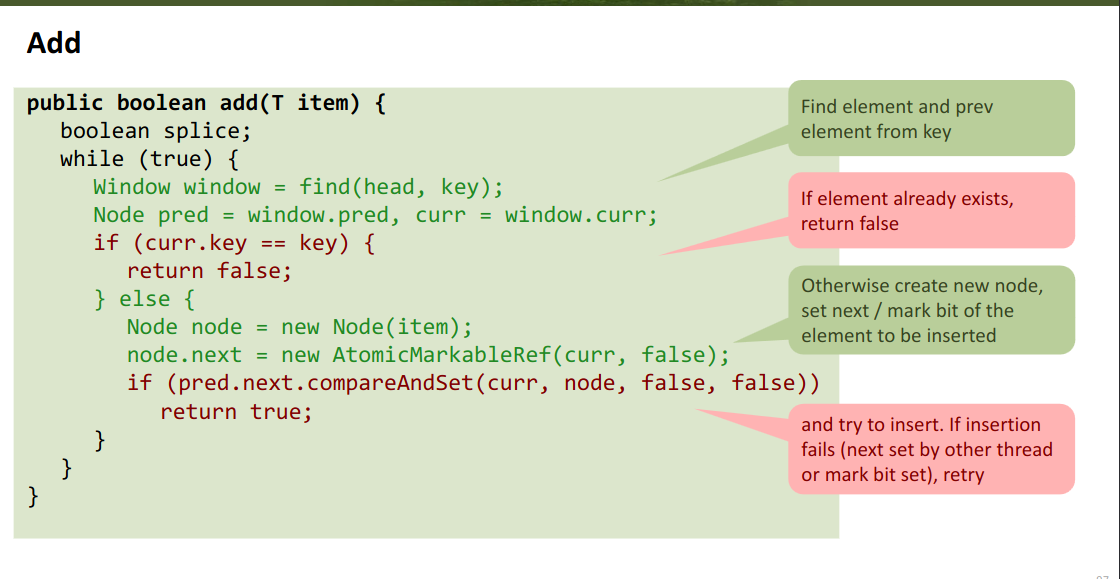
Non-blocking Stack implementation:

we use an atomic reference to the top element.
To pop/push, we:
- save current top element as a local variable
- for add: set our new elements
.next - try to CAS the new element into the top
if it fails → retry
Pros:
- Since this is lock-free → deadlock-free by design.
- slightly more performant in a real-world test
Fix we can use backoff to make the atomic operations faster → prevent contention.
13.3 Lock-Free List Set
(same thing as before, but we try to make it lock free again)
We use CAS to switch the pointers:
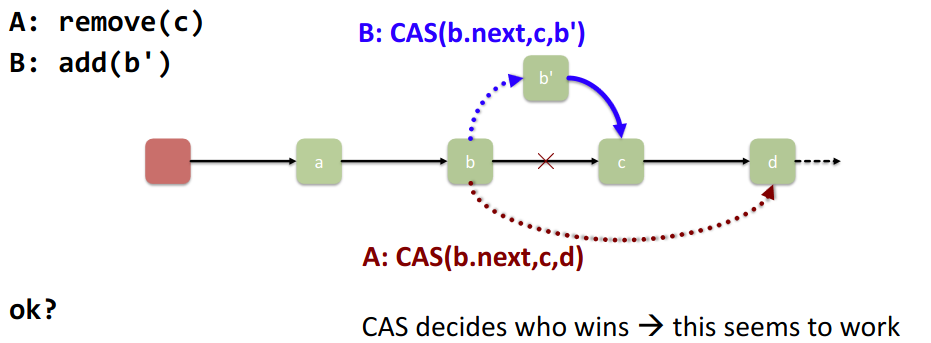
works → CAS decides who “wins” and completes the operation
Problems: Same issue as before

we fixed this before by using mark-bits. Let’s see if we can fix it the same way:
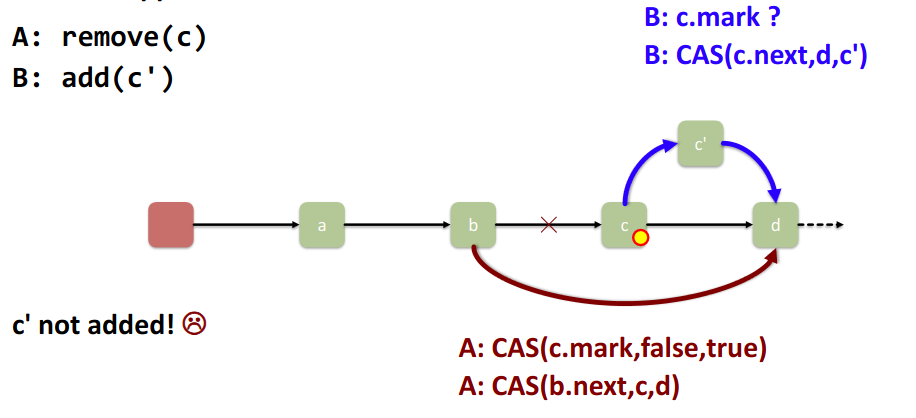
since B can be interrupted now (with locks we couldn’t have accessed c or d)
→ A can complete before B can → corrupts the state
This is a fundamental problem → we can’t “atomically” update / check both atomic variables.
→ want to atomically establish consistency of two things
13.3.1 AtomicMarkableReference
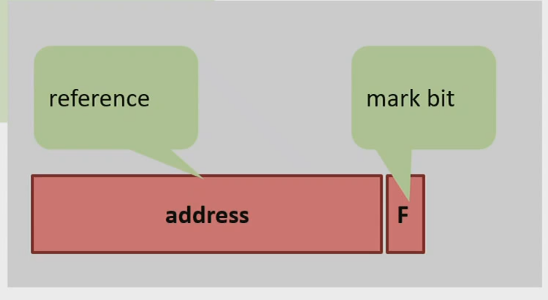
The solution to our problem from before (update / do two things “at once”) is an AtomicMarkableReference.
This works since we can just use a “free” bit in the address pointer.
- In a 64-bit system, the addressable memory space is so large that removing a few bits doesn’t change anything (nobody has 9 trillion petabytes…).
Java provides AtomicMarkableReference<V> to address this. It atomically manages a reference V and a single boolean mark.
compareAndSet(expectedRef, newRef, expectedMark, newMark): Atomically sets the reference tonewRefand the mark tonewMarkif and only if the current reference isexpectedRefAND the current mark isexpectedMark.attemptMark(expectedRef, newMark): Atomically sets the mark tonewMarkif the current reference isexpectedRef.- Other methods:
get(),getReference(),isMarked(),set().
This effectively provides a way to perform a Double CAS (DCAS) on the reference and the mark bit together.
13.3.2 Lock-free List-Set Stack with AtomicMarkableReference
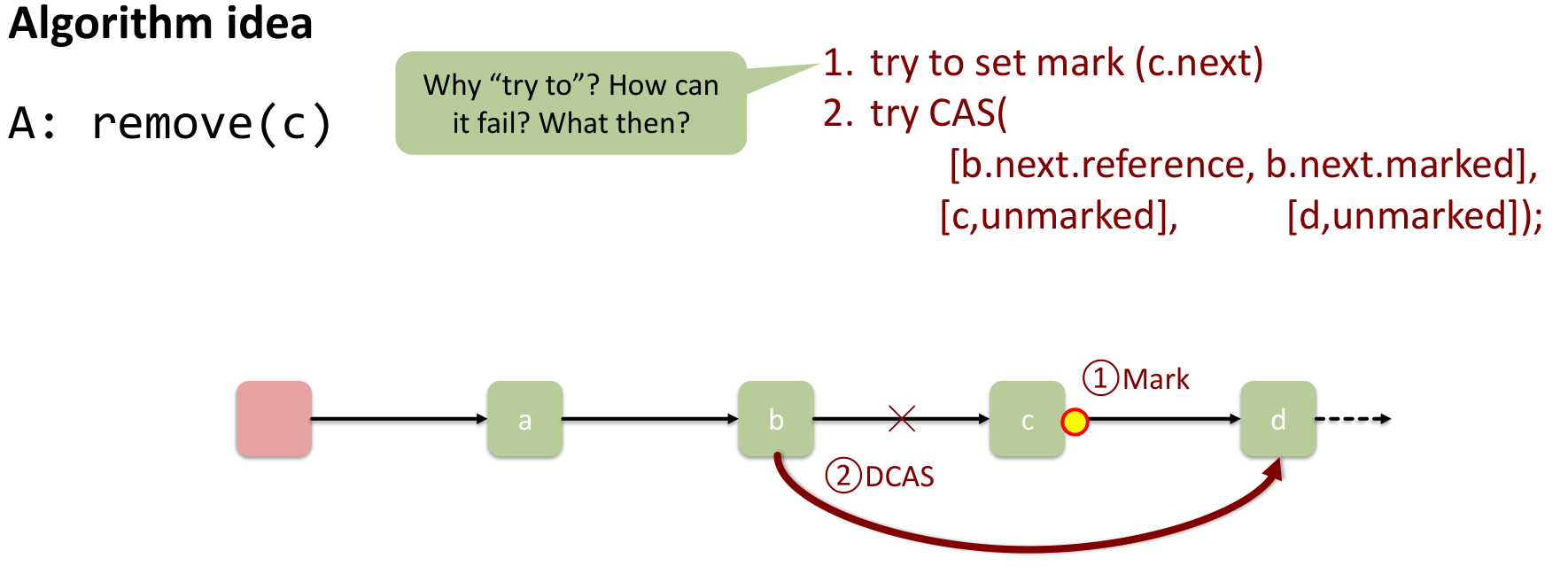
remove:
- logical delete try to set mark on
c(set mark onc.nextas that’s where we store the mark)- this could fail if someone inserted after
cfor example - or concurrent remove
→ retraverse and retry
- this could fail if someone inserted after
- physical delete: we atomically set
b.next=(c, false)(→ that means next is c and it’s not marked) to(d, false)via CAS
This prevents the previous failure mode!
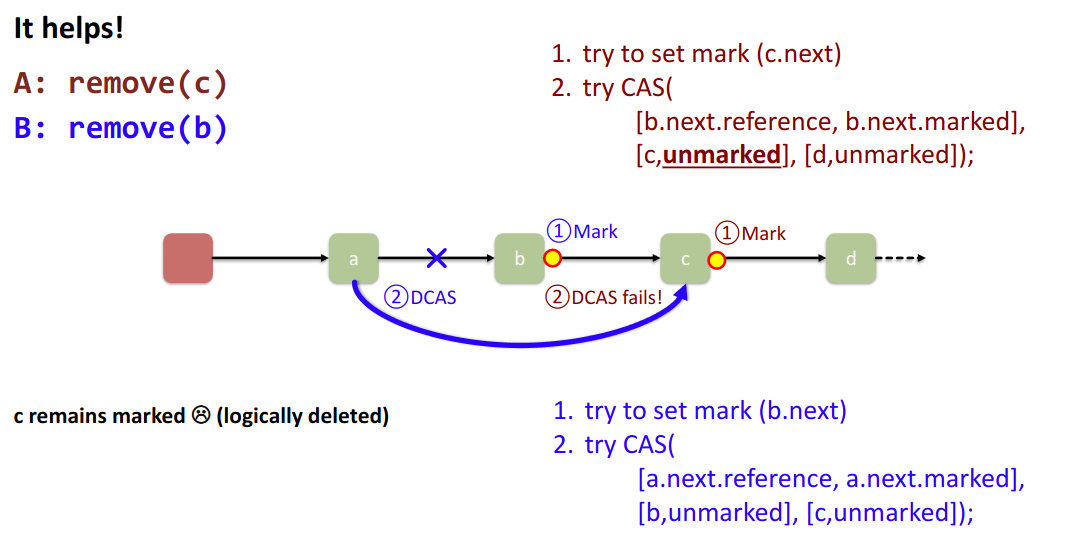
remove(c) fails because it’s marked itself now → still logically deleted so it’s fine.
Clean-up the clean-up is done when you find a marked node in your path → CAS the previous node’s .next to the one after.
→ any thread can do this!
the “helping” is a classic pattern in lock-free programming to help all threads make progress.
Full Code

the blue part is the “new” clean-up routine.
To prevent contention of many threads trying to repair the same thing → add randomness.
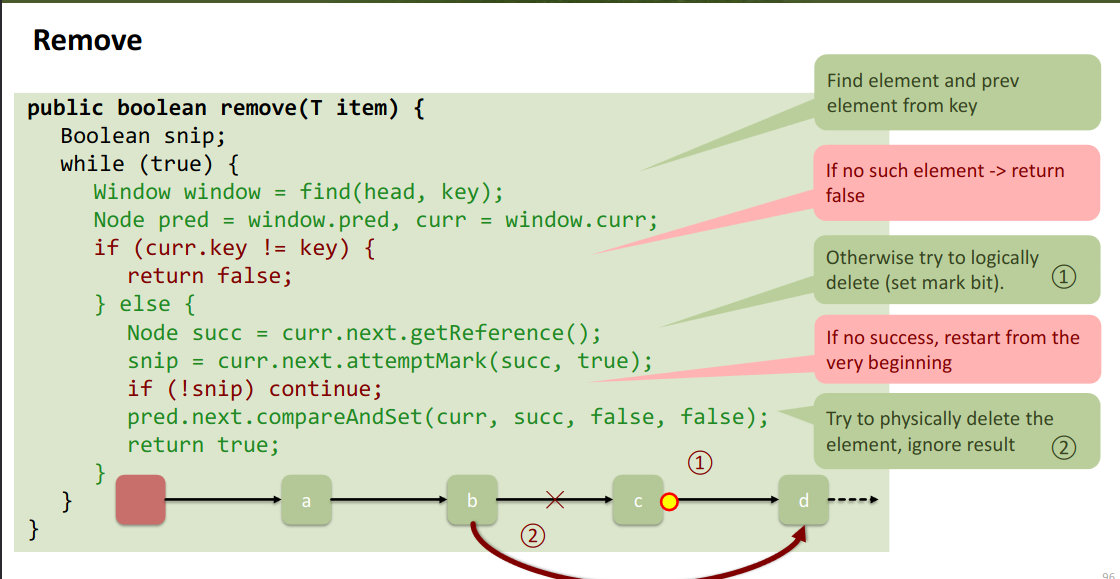
remove ops:
- CAS for marking
- if the CAS fails → retry from start.
- otherwise, try to physically delete the element.
- If that fails, we just ignore it (logically deleted anyways)!
13.4 Lock-Free Unbounded Queue
This is a datastructure needed in the OS for example (see the BKL in Linux).
Operations the following is a locked implementation.
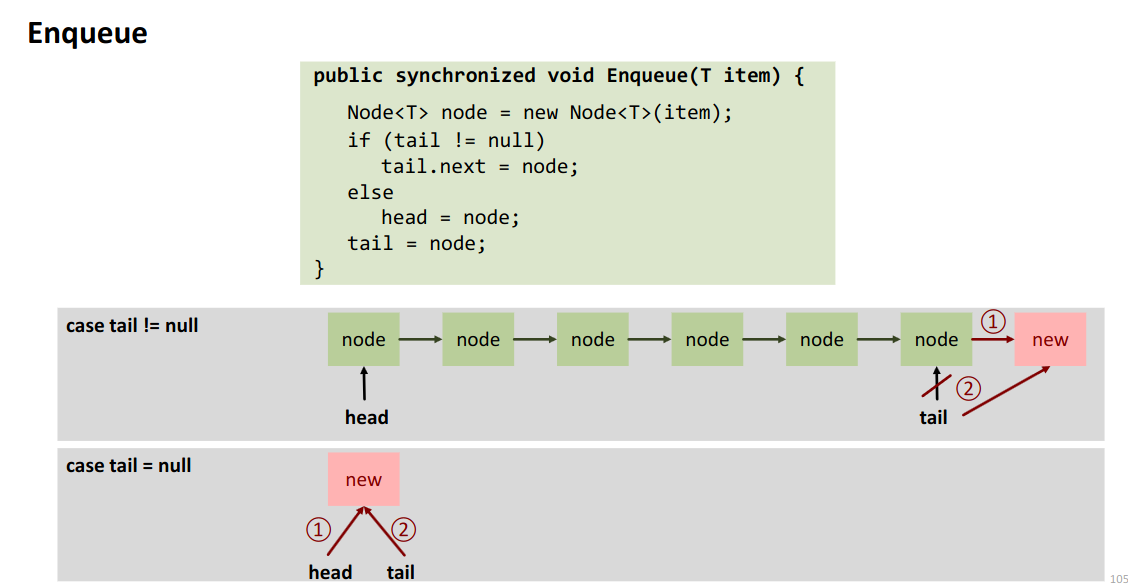
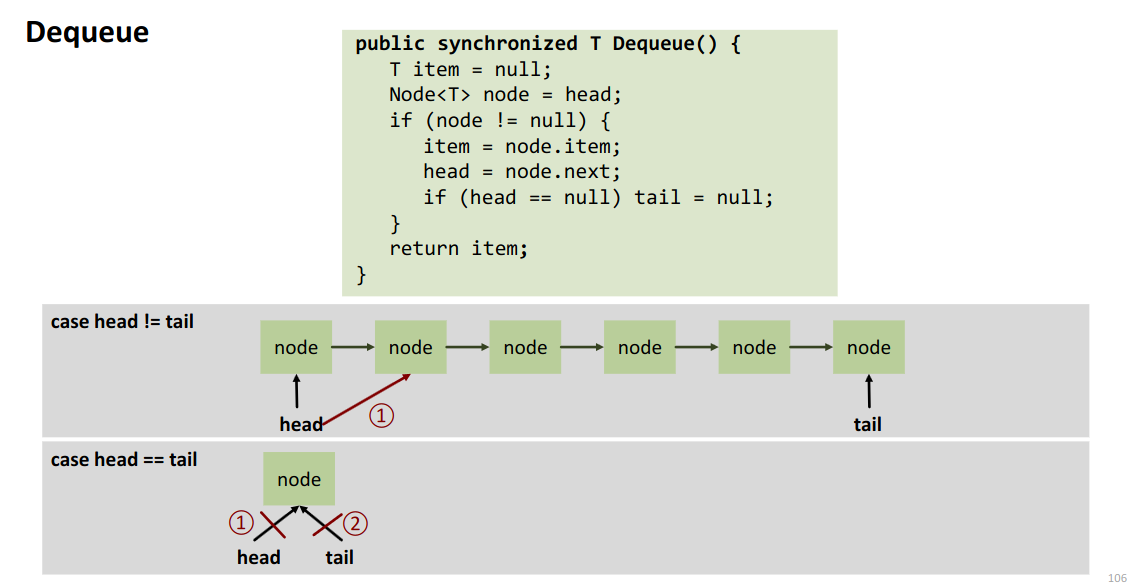
Problems in a lock-free version. Potentially simultaneous updates of
- head (dequeue)
- tail
- tail.next (enqueue)
Fix? Sentinel value
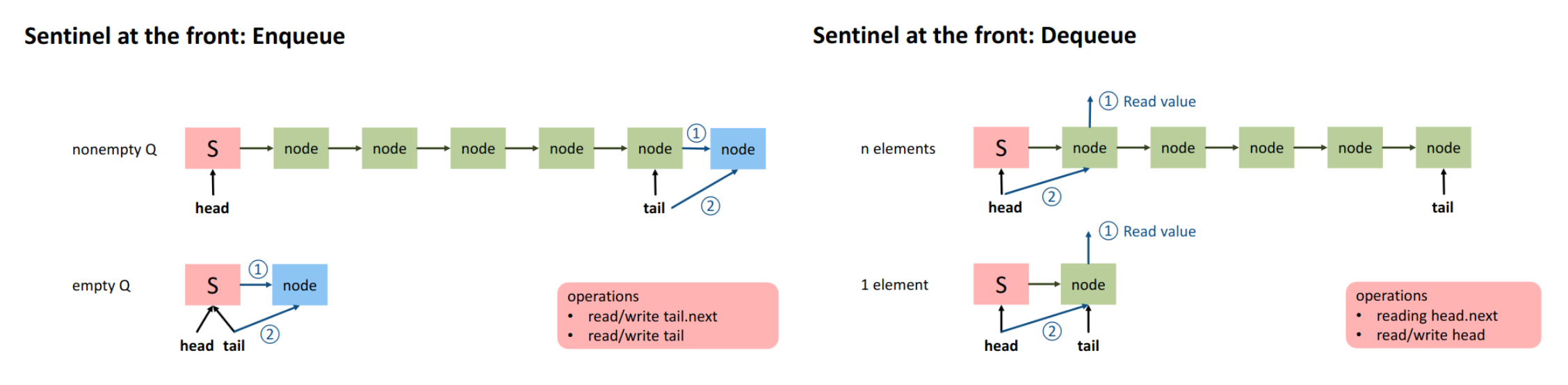
→ still problems:
- still have to update two pointers at a time
- possible inconsistency
- tail might transiently not point to the last element
a thread might have to wait until consistency is established → lock camouflaged
solution: threads help making progress
- tail might transiently not point to the last element
13.4.1 Atomic Version
We add atomic references.
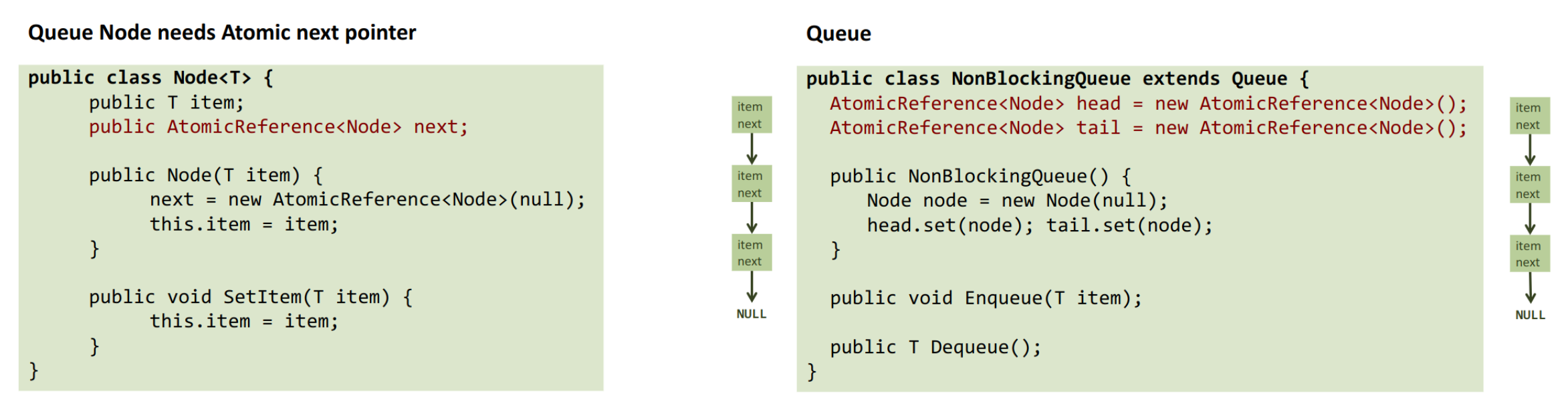
Protocol:
enqueue- read tail into last
- then tries to set
last.nextCAS(last.next, null, new)
- retry
- otherwise, try to set tail
- without retry → “logically only” if it fails
dequeue- read
headintofirst(the sentinel) - read
first.nextintonext(nextis the item to dequeue) - if next is available, read the item value of
next(the value we pop and return) CAS(head, first, next)(set head to the new “sentinel”)- if unsuccessful, retry
- read

enqueue’s CAS might fail because:
- another thread pre-empted me
- I read a stale
tail- missed update of another thread
- other thread failed in updating
tailbecause it just died- that’s where the helping comes in → update tail for the other thread
Another Failure mode mixing enqueue and dequeue
![]()
Again: that’s where the helping comes in → update tail for the other thread
Final Solution: with helping other threads

if next is not null anymore → tail is not last element → we clean-up: update the tail to the new last.

in the edge-case of a element queue → check for tail pointing to dequeued element.
13.5 Recap
Difference between blocking vs. non-blocking:
- blocking may wait indefinitely for another thread
- non-blocking must not wait indefinitely ever! (so no locks)
- even without locks → we might get into a “soft-lock” situation if not careful
Use CAS:
- the more data-items needed to keep in sync the harder
- need DCAS to update multiple values atomically
- learned some tricks:
- fake DCAS (atomic, markable reference)
- helper principle
- use logical and then physical deletion
- the logical deletion only needs single atomic update
- sentinel values