We need to formally define these terms:
- consistency
- linearizability
- consensus
→ a language to talk about concurrency
Running example: Bounded FIFO queue with a single enqueuer and dequeuer

this is correct for single enqueuer/dequeuer → only one thread updates head, only a single thread updates tail → no conflicts.
How can we prove this correct?
Could we use sequential correctness logic like Floyd-Hoare logic to prove this?
in sequential we don’t care how long each invocation takes → in concurrent this starts to matter.
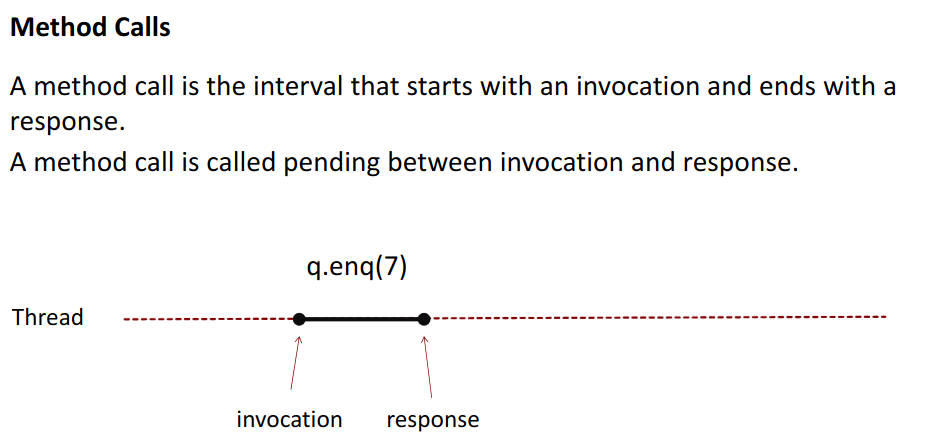

We look at a blocking queue in this graph, in real time:
Now the question: which thread got the lock first?
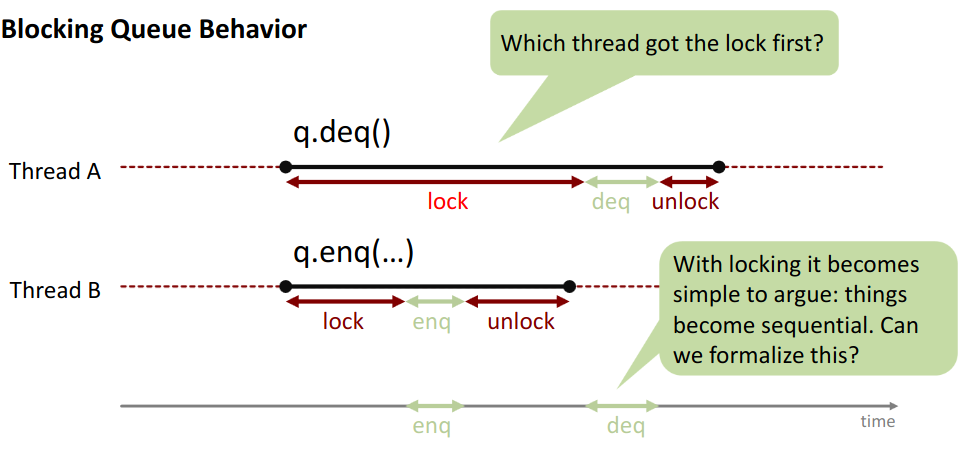
locks project onto a single sequential timeline!
Locks don’t tell you which order happened. They guarantee that A happened before B or B before A → nothing else possible!
15.1 Linearizability
Each method should appear to take effect instantaneously between invocation and response events.
→ this might be wrong in a bad memory model (we have to use volatile everywhere…)
An object for which this is true for all possible executions is called linearizable → the object is correct if the associated sequential behaviour is correct.
Formalism
An execution history
His linearizable if it can be mapped (by completing/removing pending calls) to a historyGsuch that:
Gis equivalent (same per-thread projections) to a legal sequential historyS(obeys sequential object semantics, e.g., FIFO).Srespects the real-time order ofG: if operationm0finished before operationm1started inG, thenm0must come beforem1in the sequential historyS. (→S ⊂ →G).
Example:

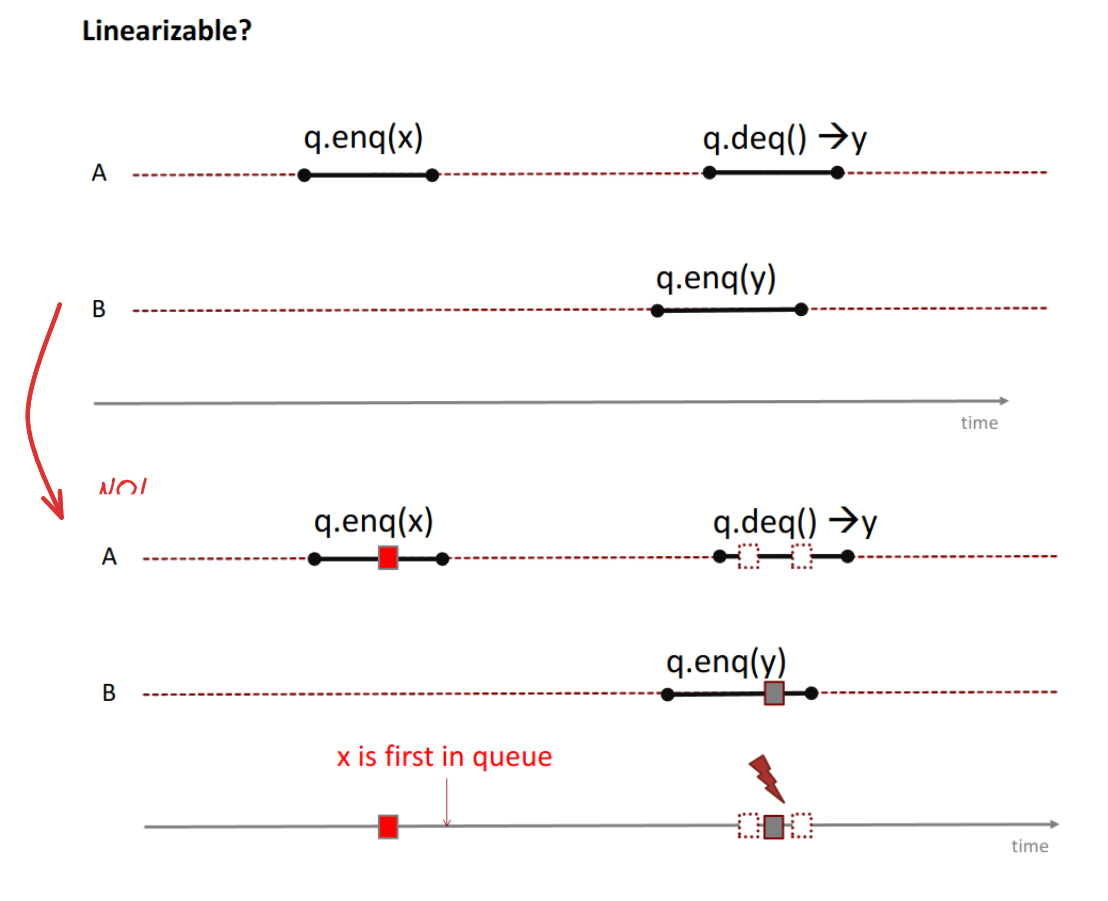
This would be linearizable if the q.enq(x) prolonged up until the q.enq(y) !
Example of a Read/Write Register
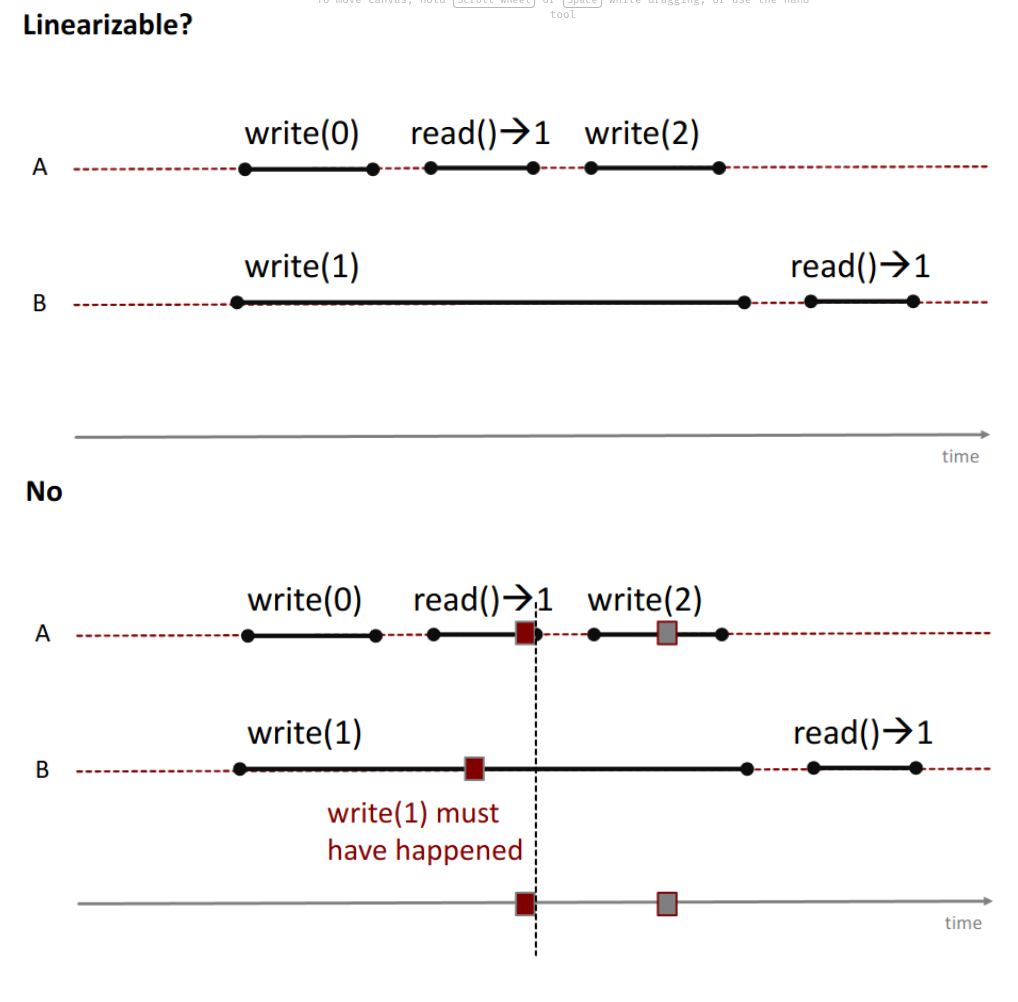
Some important conceptual notes on this new formalism:

→ deq has two possible executions → two different linearization points
That is why we look at the timelines.
Linearize
Meaning the operation is complete and visible to others as if it happened at that exact point in time, i.e. it takes effect.
Linearization Point
The specific point in time where an operation linearizes might depend on the execution path (e.g. whether a bounded queue is empty of not).
It’s not always a fixed line of code but rather a dynamic point during execution.
Note: there is one linearization point per call of a method (not per method).
WARNING
There cannot be two linearisation points in a single method code path.
Ex: successful dequeu has one linearisation point when the tail is changed.
15.1.1 A Formalisation
Instead of drawing diagrams, we can also use a textual representation.
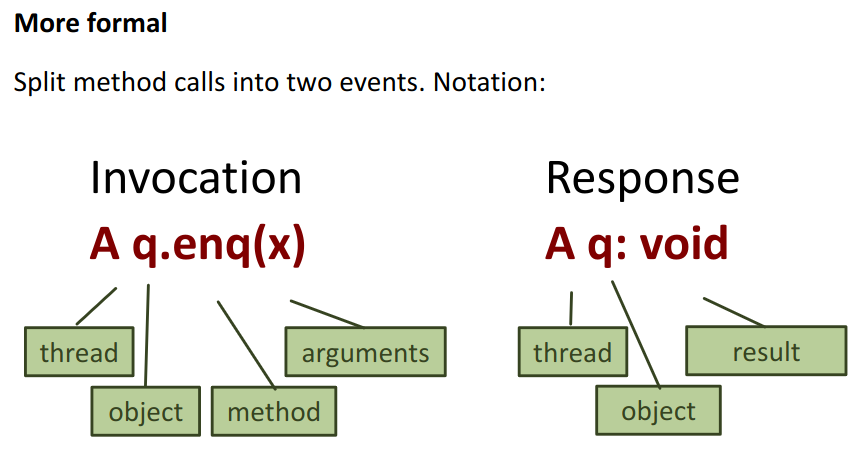
This is exactly equivalent to the image from before, but in text form:
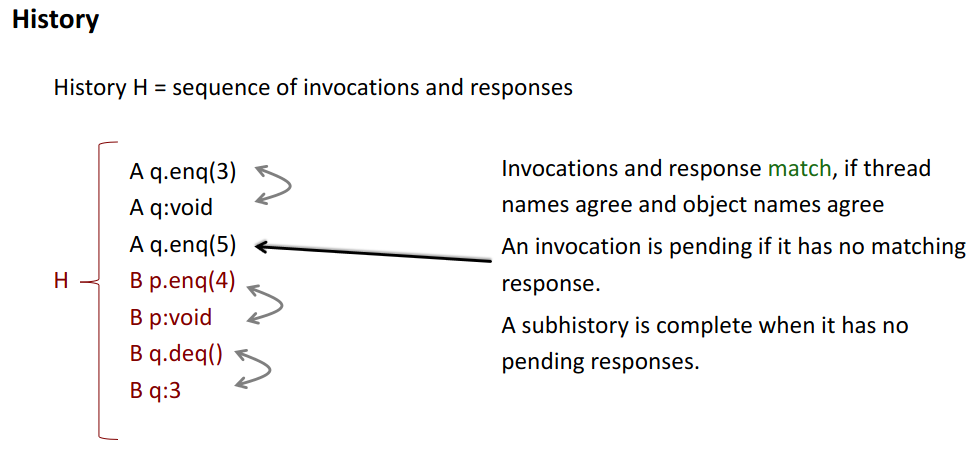
We can then create so-called projections → we simplify onto one “axis”:
- for each object
- for each thread

We can then define some terms: Complete subhistory

A complete subhistory has no pending invocations.
Sequential history

→ method calls of different threads do not interleave.
Well-formed history

→ if every per-thread project is sequential, the history is well-formed
Equivalent histories

→ same results, just different order.
Legal histories

A sequential history is legal, if for every object x:
H | xadheres to the sequential specification ofx- satisfies pre/post conditions
- ex: obeys FIFO rules for a queue
Difference legal vs. well-formed:
- well-formed only means that for the same object the calls match
- the wrong returns could come out.
- legal only if they actually do the right thing
Precedence
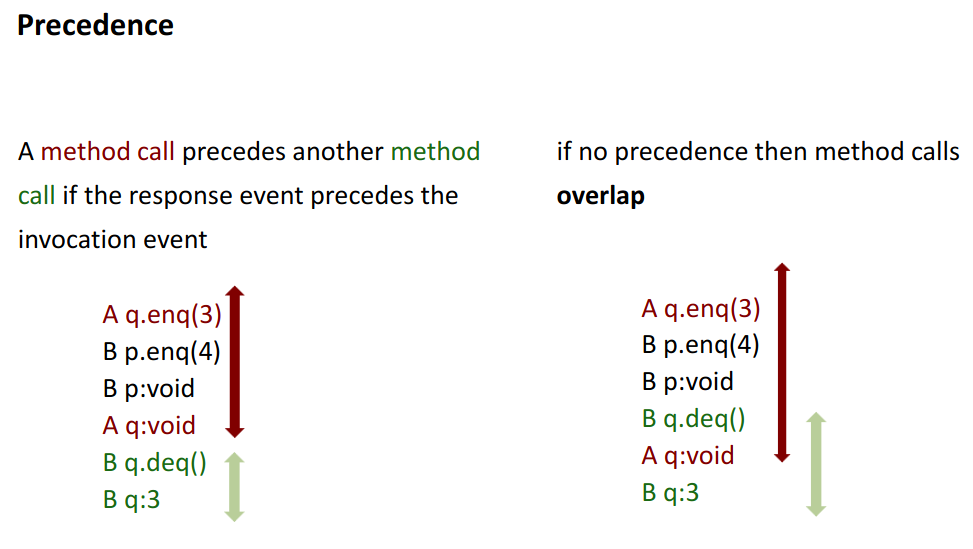
→ only if actually separated, i.e. finished before the other started
we denote this in the following way:

this gives us a partial order.
This partial order is even total but only when is a sequential order!
Linearizability

What we actually want: take the history and actually decide a “real order” which is legal → same thing we did before on the example slides.
Definition of taking effect:

- B:
q.deq()has occurred and returnedxthusAmust have taken effect!
→ we add a response to the pending call inA. - C:
flag.read()can be removed as nothing is relying on this
Definition of
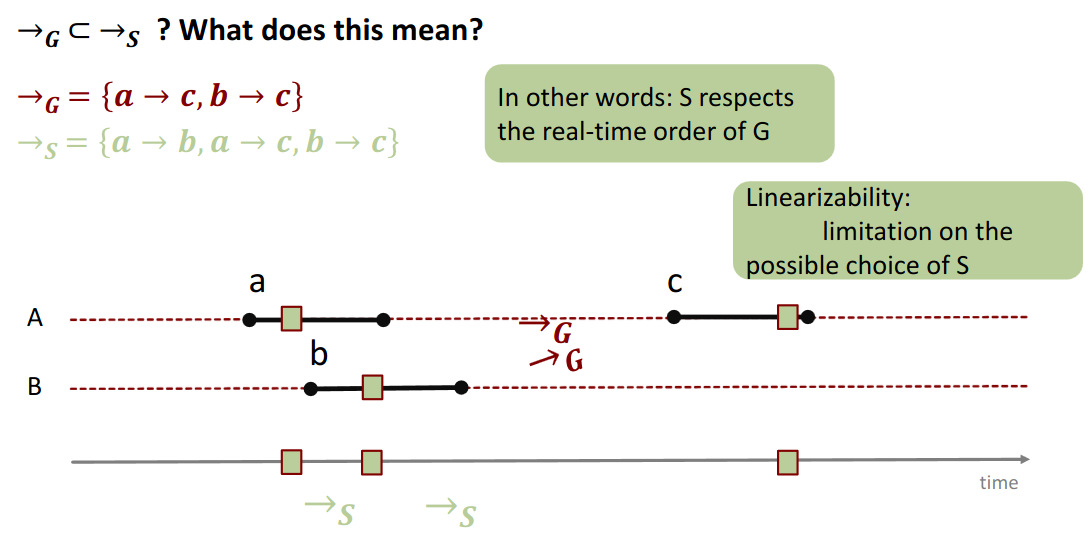
The order tells us that a, b happened before c
→ Can we find linearisation points (i.e. an actual order in which things occur), for this to be possible and get a total order.
15.1.2 Properties and Reasoning Strategy
If all objects are linearisable, since they don’t interact → we can compose them.

In practice, we want things to write code that is linearisable.
15.1.3 Examples in Practice
Atomic registers (the basic building blocks of our locks, etc…) are inherently linearizable.

Example Linearizability with locks on a bounded FIFO queue.

Example Linearizability Wait-free bounded Queue

Example Lock-free example

Error
The 2nd point shown there is not a linearization point.
The tail pointer is not part of the queue → just a helper. Thus updating it actually isn’t a linearization anything!
It’s just the helping → we loop around again anyways, so this can never be the end of the method.
Identifying Points:
- Locking: Often the release of the lock, or the key update within the critical section.
- Wait-Free/Lock-Free: Typically the single successful atomic instruction (like CAS or an atomic increment) that achieves the operation’s core effect.
→ Strategy: To prove linearizability, identify a linearization point for each operation such that the resulting sequential execution is always legal and respects the real-time partial order.
15.1.4 Recap

If it doesn’t work, we can decompose methods into several sub-methods with a linearization points at each point.
15.2 Sequential Consistency
Is a weaker alternative to linearization.

but the difference is that:

SC allows non-overlapping operations performed by different threads to be re-ordered in compared to their actual execution order in .

15.2.1 Comparing SC and Linearizability
Example: Queue example
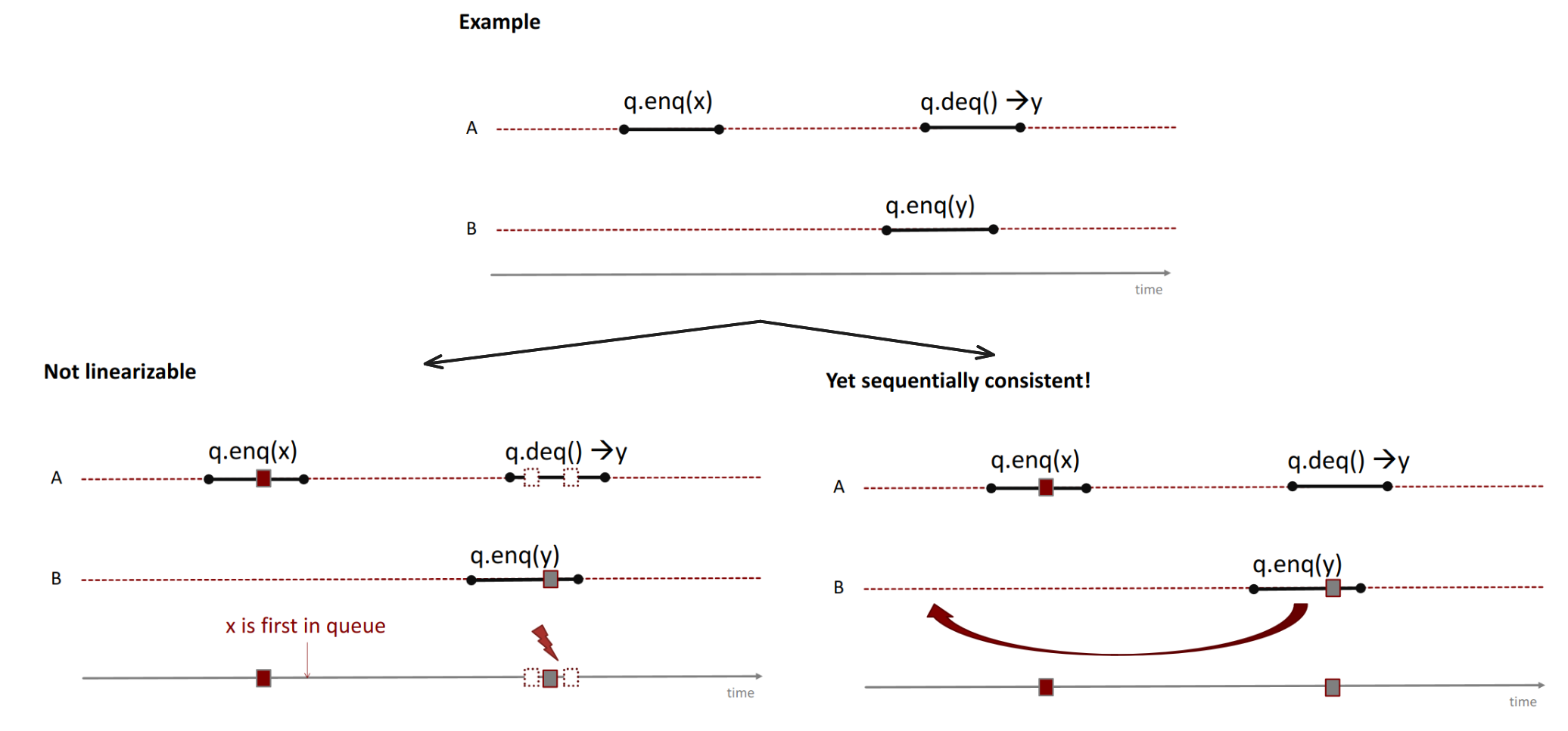
It’s not linearizable because x is first in the queue.
→ we cannot reorder non-overlapping sections.
- there’s no linearization point for
q.enq(x)which would make it happen afterq.enq(y)
Yet, this is sequentially consistent. We can simply move the q.enq(y) in front of q.enq(x) because it happened on a different thread.
→ only thread-internally sequentially consistent.
Composability
Sequential Consistency is not a local property.
Thus we lose composability.
Example of non-composability.
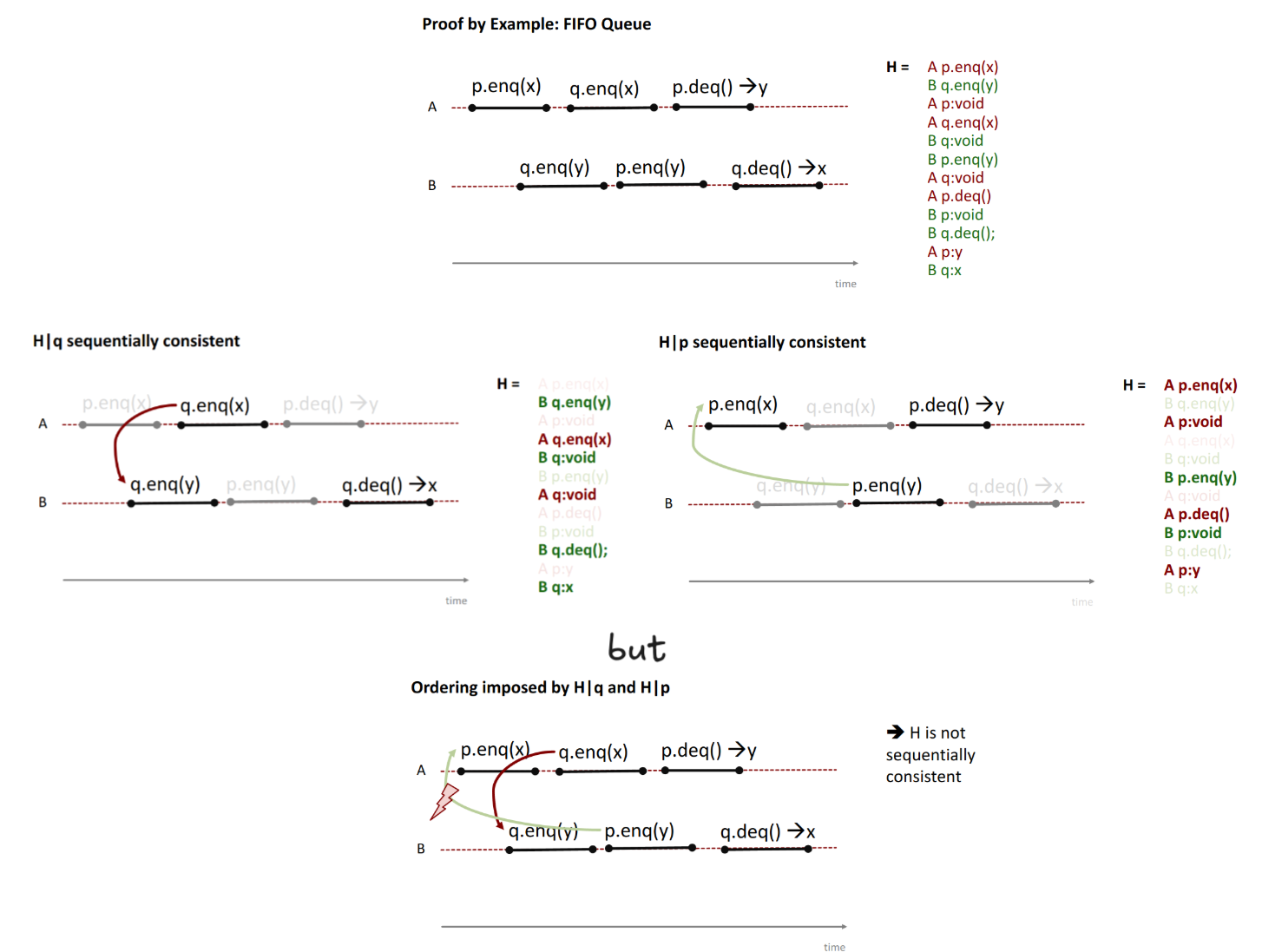
Even though both projected histories are SC, the ordering imposed by their composition is not → we get a cycle.
→ local sequential consistency still imposes an ordering which breaks this!
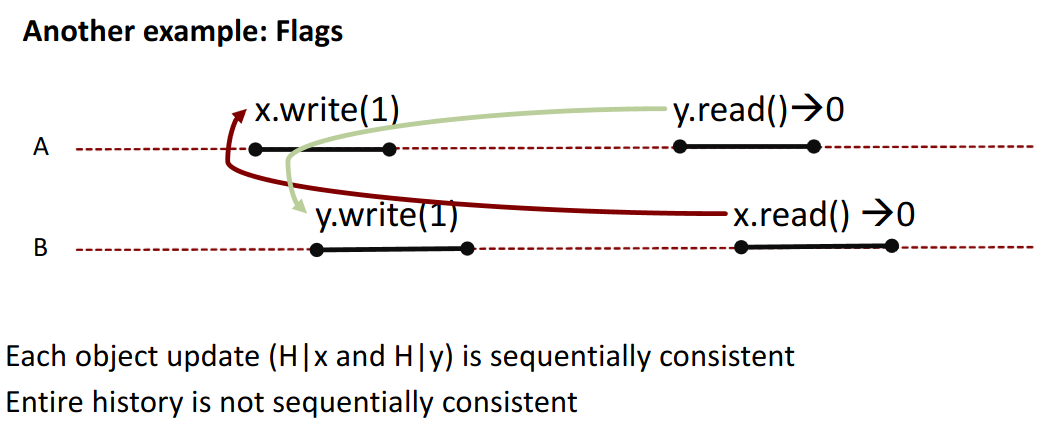
Example 2 for non-composability
Example Peterson Lock (flag principle)
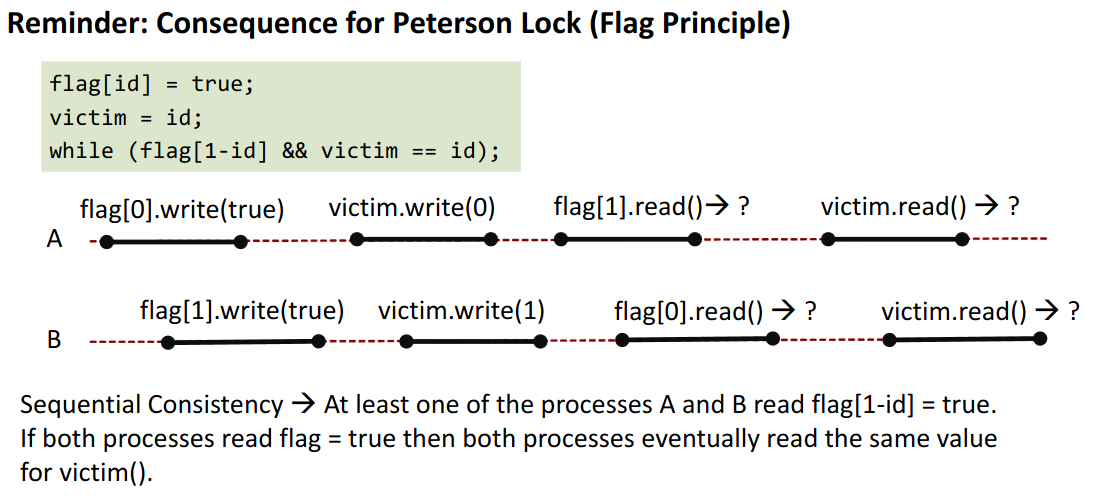
Thus, we guarantee that the lock works! Any other execution cannot be reconciled with SC.
If we had:
flag[1].read() -> falseandflag[0].read() -> false- and
victim.read()reads the other for both
thus if both are in the Critical Section → we have an issue since we assume sequential consistency for our memory model.
This principle of “either you see no changes” or “you see all of them” is necessary for the Peterson lock.
- either we see
falsefor the other flag → but then we read that we are the victim ourselves - or we read
truefor other flag and then we can have the victim be the other one.
15.2.2 (Side Remark) Quiescent Consistency
We define a partial ordering between period where nothing happens.

But anything may happen when calls overlap → we can reorder them any way we like.
This kind of makes sense in a database system, where when nothing happens a clean-up process runs or something.
Examples: SC is not consistent with QC.
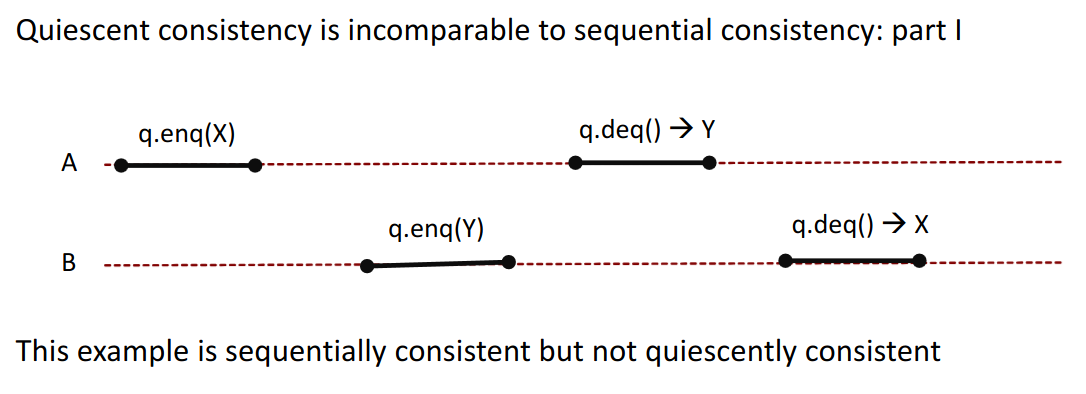
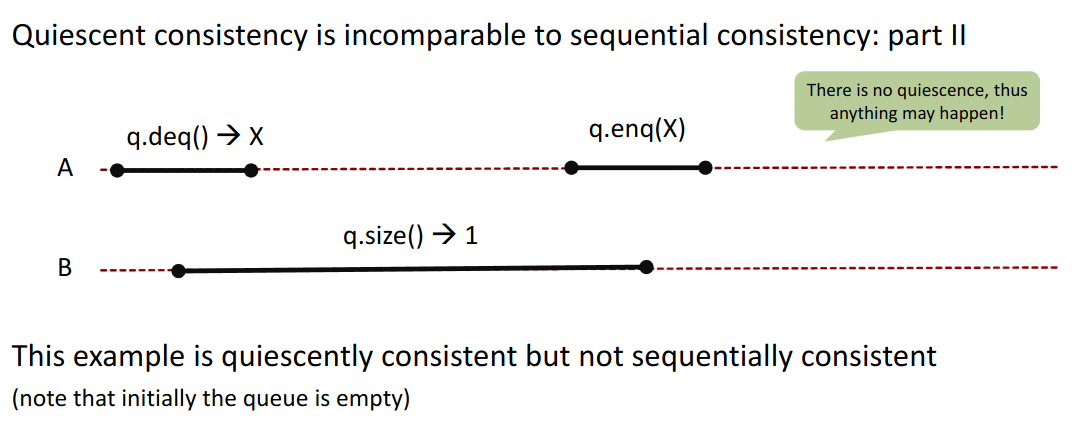
As we see in the second example, we can even move things around intra-thread (in thread A) as the calls all overlap.
15.3 Final Remarks

This is actually good, as in modern hardware if we upheld SC, we’d have really slow memory/cache interfacing
→ we want cache!

We then explicitly ask for synchronization.
We need volatile to get the flag principle to be requested in many memory models → see Java.

Real-World-Hardware Memory has weaker guarantees than sequential consistency.
But you can get it at a price.
Concept of linearizability is more appropriate for high-level software.
Final comparison:

Cache coherence is only true for reading from cache.
→ does not have that guarantee for the write-buffers.