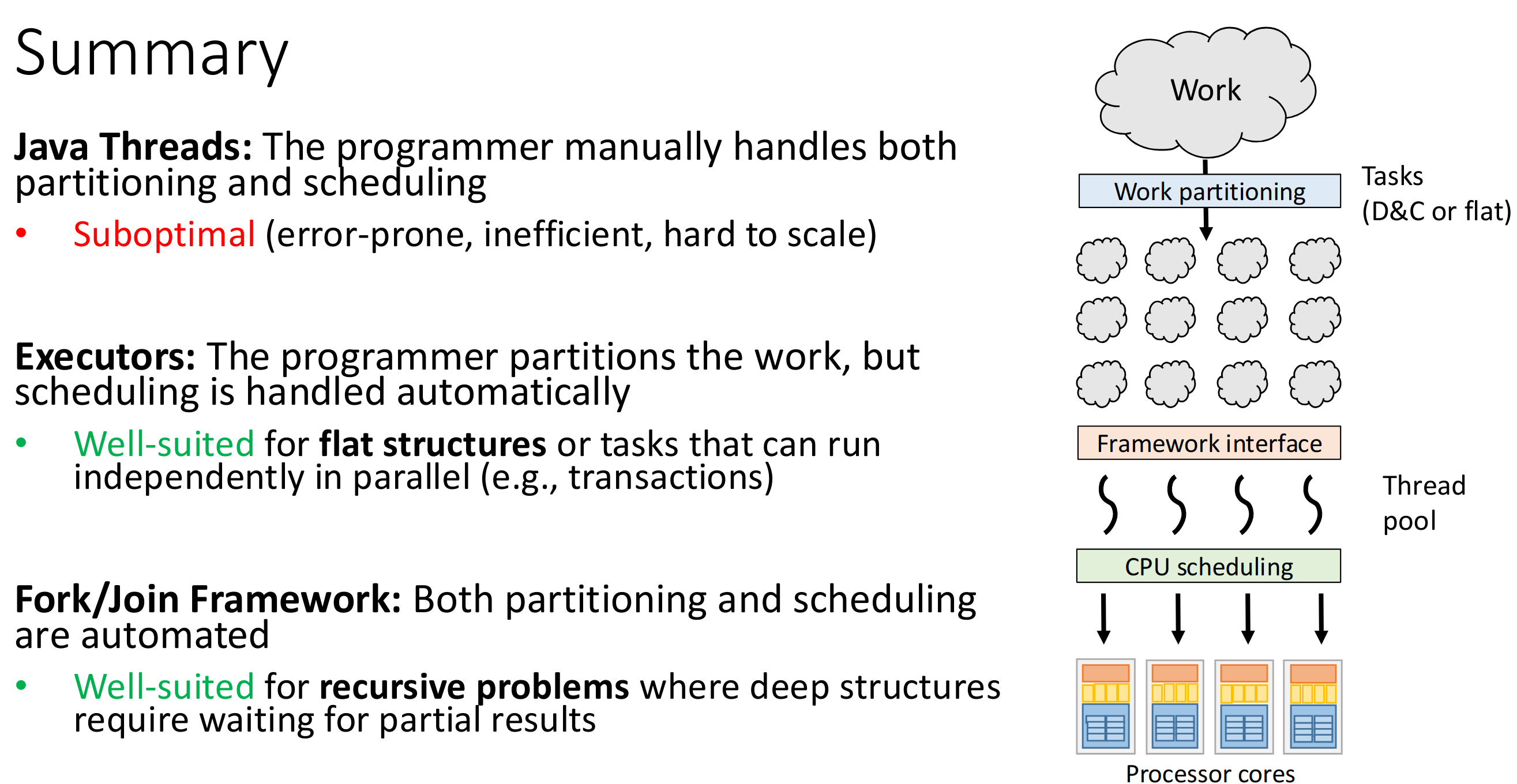
5.1 Fork/Join (also called Cilk-Style)
Example of summing together all the values of the array. In a naive parallel program, we could divide the array beforehand, into distinct pieces and then run a thread to compute the “sub-sum” for each part.
This has a few issues:
- Processor Utilisation what if the number of available cores changes during execution? We can’t just create more threads
- Load Imbalance what if some parts of the array take longer to sum up
This is where fork/join style programming comes in. We just create a fuckton more “threads” (which in reality are tasks handled by a pool of threads) which solves the issue - divide and conquer style.
5.1.2 Manual Fixes
We can fix the issue of creating too many threads (two per recursive step in the case of summing), by creating one and doing the other half of the work in the main thread directly.

The second version reduces the number of Threads needed by x2.
We can also set the cutoff higher, which reduces the overhead by better utilising the Threads.
However this is still not optimal, as we still create Threads, which creates overhead and is very wasteful on deep recursion trees.

Note that each task should perform between 1k and 100k sequential operations in order to guarantee they have enough work to do.
5.1.3 Usage
ForkJoinPool pool = new ForkJoinPool(); // or ForkJoinPool.commonPool()RecursiveTask<V> (returns result)
class SumTask extends RecursiveTask {
private final int[] arr;
private final int lo, hi;
private static final int THRESHOLD = 1000;
SumTask(int[] arr, int lo, int hi) { this.arr = arr; this.lo = lo; this.hi = hi; }
@Override
protected Long compute() {
if (hi - lo <= THRESHOLD) {
long sum = 0;
for (int i = lo; i < hi; i++) sum += arr[i];
return sum;
}
int mid = (lo + hi) / 2;
SumTask left = new SumTask(arr, lo, mid);
SumTask right = new SumTask(arr, mid, hi);
left.fork(); // async execute left
long rResult = right.compute(); // compute right in current thread
long lResult = left.join(); // wait for left
return lResult + rResult;
}
}
// Invoke
Long result = pool.invoke(new SumTask(arr, 0, arr.length));RecursiveAction (no return value)
class SortAction extends RecursiveAction {
@Override
protected void compute() {
if (small) { /* base case */ }
else { invokeAll(leftTask, rightTask); }
}
}| Method | Description |
|---|---|
fork() | Submit subtask asynchronously |
join() | Wait for and get result |
compute() | Execute task logic |
invoke(task) | Submit + join (blocking) |
invokeAll(a, b) | Fork all, join all |
5.2 Executor Service
The executor service has the issue that if we have a deep recursion tree which necessitates a lot of waiting (dependent tasks), we might eventually run out of threads.
It is therefore more suited for flat structures (independent requests, standalone tasks).
Thread-Starvation
All threads executing in the pool are blocked on tasks that are waiting for a thread in the internal queue.
5.2.1 Usage
Setup
// Fixed pool
ExecutorService exec = Executors.newFixedThreadPool(4);
// Single thread
ExecutorService exec = Executors.newSingleThreadExecutor();
// Cached (elastic)
ExecutorService exec = Executors.newCachedThreadPool();
// Scheduled
ScheduledExecutorService exec = Executors.newScheduledThreadPool(2);Submit Tasks
// Runnable (no result)
exec.execute(() -> doWork());
// Callable<V> (returns Future)
Future<String> future = exec.submit(() -> {
return "result";
});
String val = future.get(); // blocking
String val = future.get(5, TimeUnit.SECONDS); // with timeout
// Batch
List<Callable<String>> tasks = List.of(task1, task2, task3);
List<Future<String>> futures = exec.invokeAll(tasks); // wait for all
String first = exec.invokeAny(tasks); // first completedShutdown
exec.shutdown(); // no new tasks, finish existing
exec.shutdownNow(); // interrupt running tasks
exec.awaitTermination(10, TimeUnit.SECONDS);CompletableFuture (modern alternative)
CompletableFuture.supplyAsync(() -> fetchData(), exec)
.thenApply(data -> process(data))
.thenAccept(result -> save(result))
.exceptionally(ex -> { log(ex); return null; });Key Methods
| Method | Description |
|---|---|
execute(Runnable) | Fire-and-forget |
submit(Callable) | Returns Future<V> |
invokeAll(tasks) | Run all, block until done |
invokeAny(tasks) | Return first completed |
shutdown() | Graceful stop |
shutdownNow() | Force stop |
5.3 Trade-offs
5.4 Measuring Parallelism with the new Frameworks
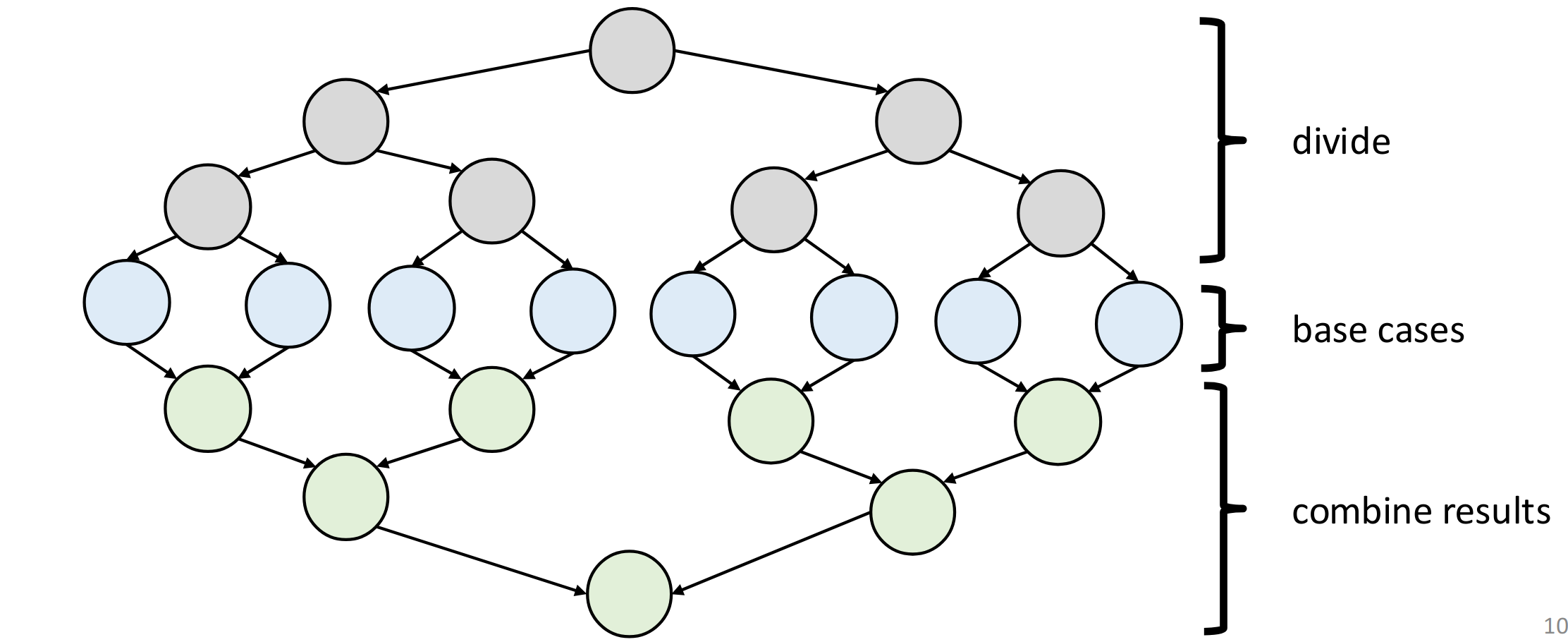
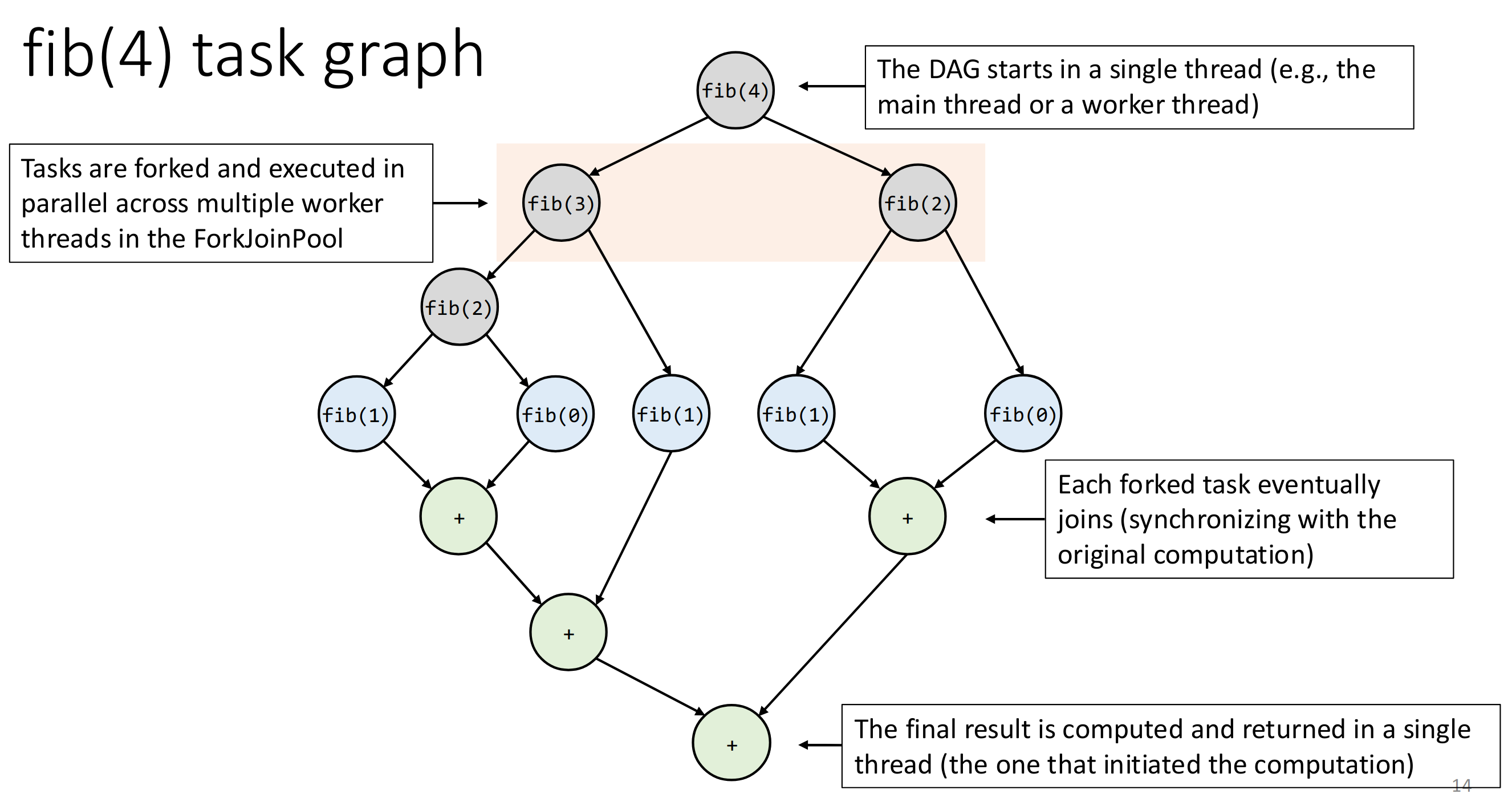
We can model the execution of a Fork/Join program using a DAG.

For a classic divide-and-conquer approach, the DAG will look as follows:
5.4.1 Task Graphs
Task-Graph
Ein Task-Graph ist ein DAG (einzige Bedingung, kann weird ausschauen).
Die Kanten stellen Dependencies dar.
Die Knoten enthalten die Runtime des Tasks (oder manchmal parameters).
Beispiel: Task-Graphs?
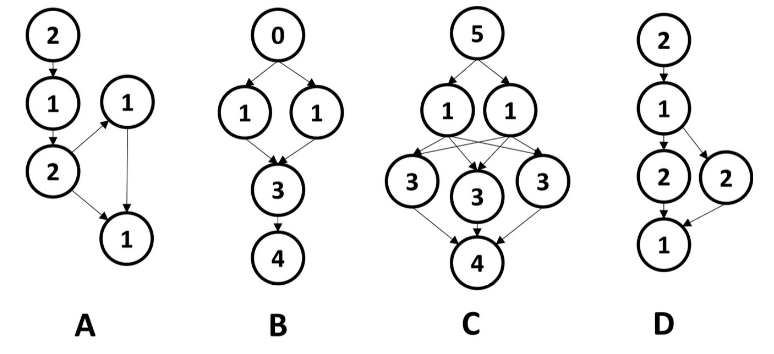
Alle dieser Graphen sind valide Task-Graphs.
Kompletter Task-Graph
Ein kompletter Task-Graph enthält auch die “joins” am Ende. Ein simplified Task Graph nicht.
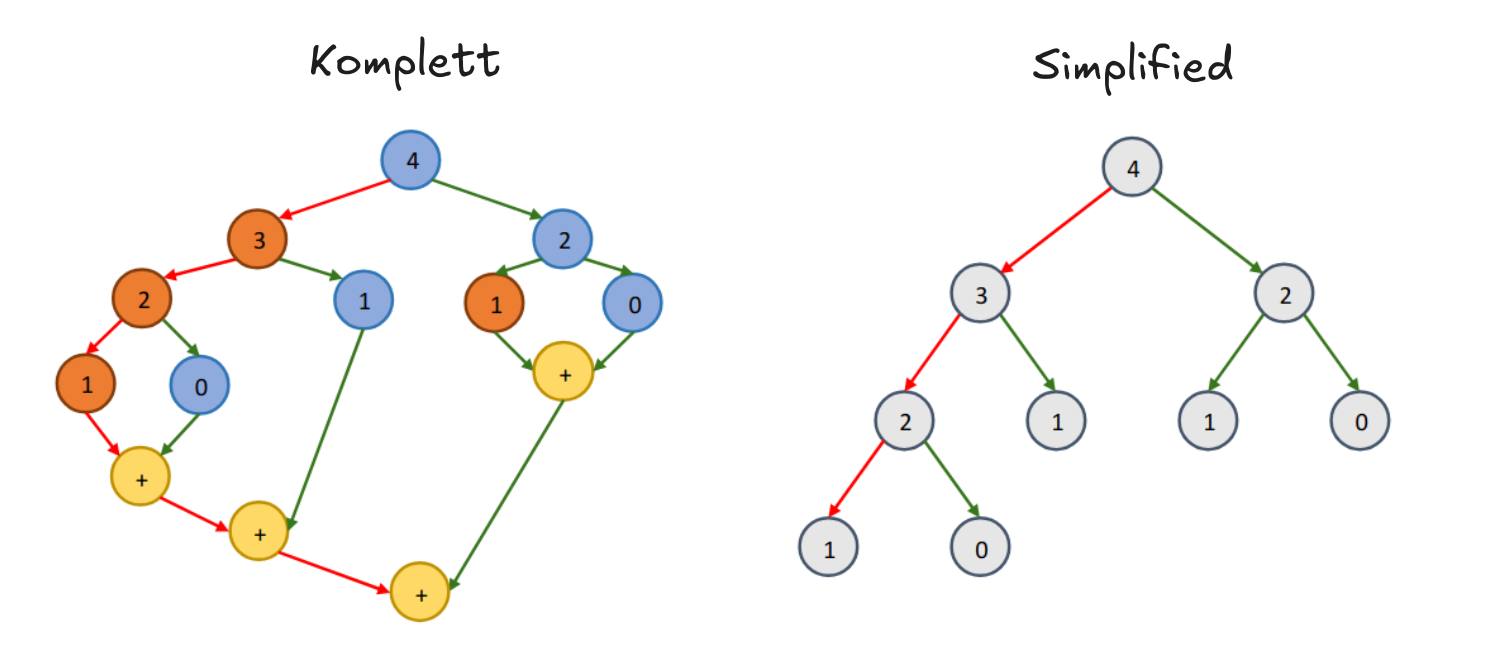
Span im Kompletten / Simplified
Für den Span zählt man Nodes auf dem Critical Path.
Man zählt trotzdem immer nur die Nodes, also ist der Span für komplett / simplified unterschiedlich.
Note that this task graph is dynamic, it unfolds as execution proceeds.
Independent nodes can but don’t have to be executed in parallel.
Example for Fibonacci
Work in a DAG
- (work): tells us total work - the sum of all task execution times
- (real world parallel performance) - how much speedup we get with threads
- (span best possible speedup) - the longest dependency chain that cannot be parallelised
We cannot control , it depends on the Scheduler, work distribution, thread contention, OS load, etc…
Example Here the scheduler could give us more or less parallel speedup:
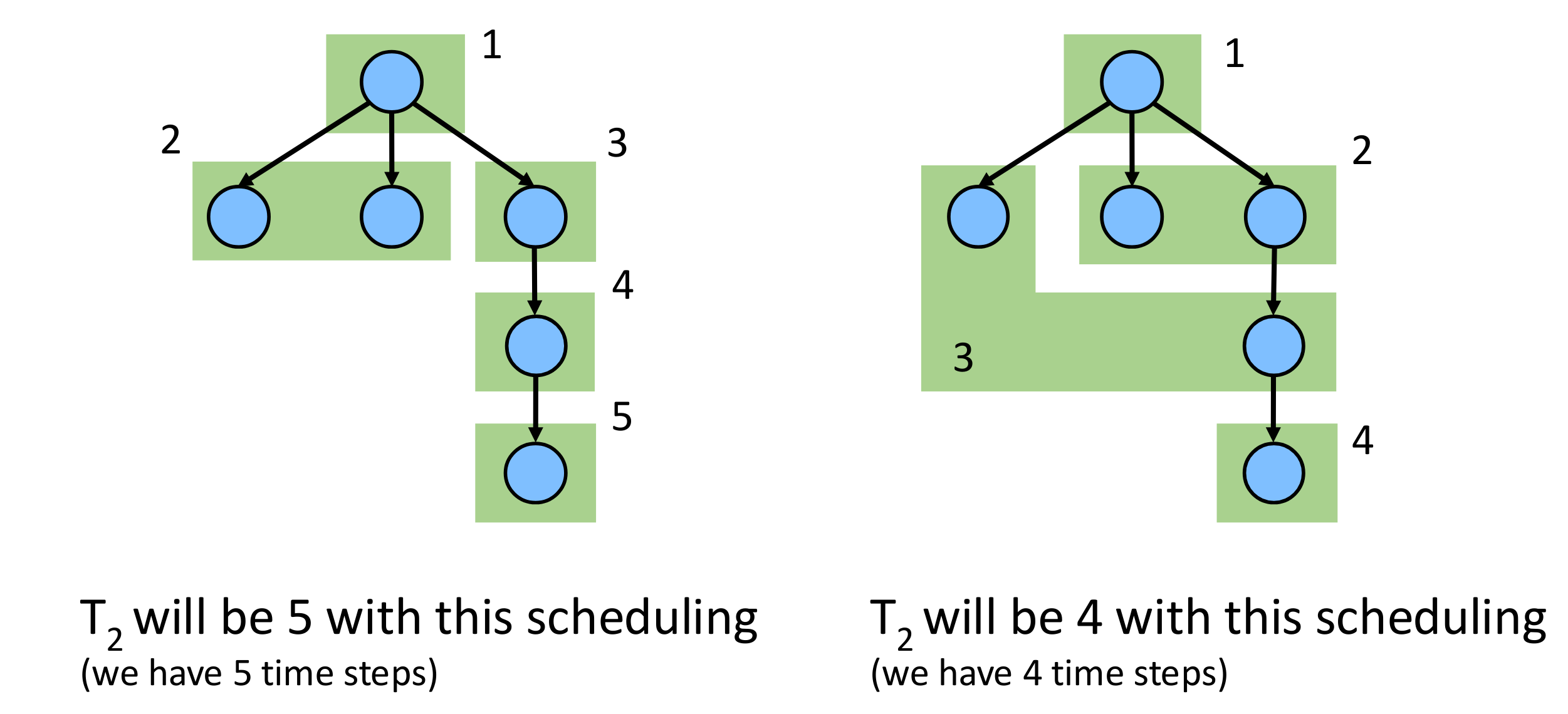
We can calculate the speedup for this deep example graph and see the limits.

On this graph, we have , thus even with infinite threads, the maximum speedup is 2. The bottleneck is the span.

Note that the span is the sequential fraction of work in Amdahl’s Law. We want to reduce the span in order to increase speed-up.
5.4.2 Extract Runtime from Graph
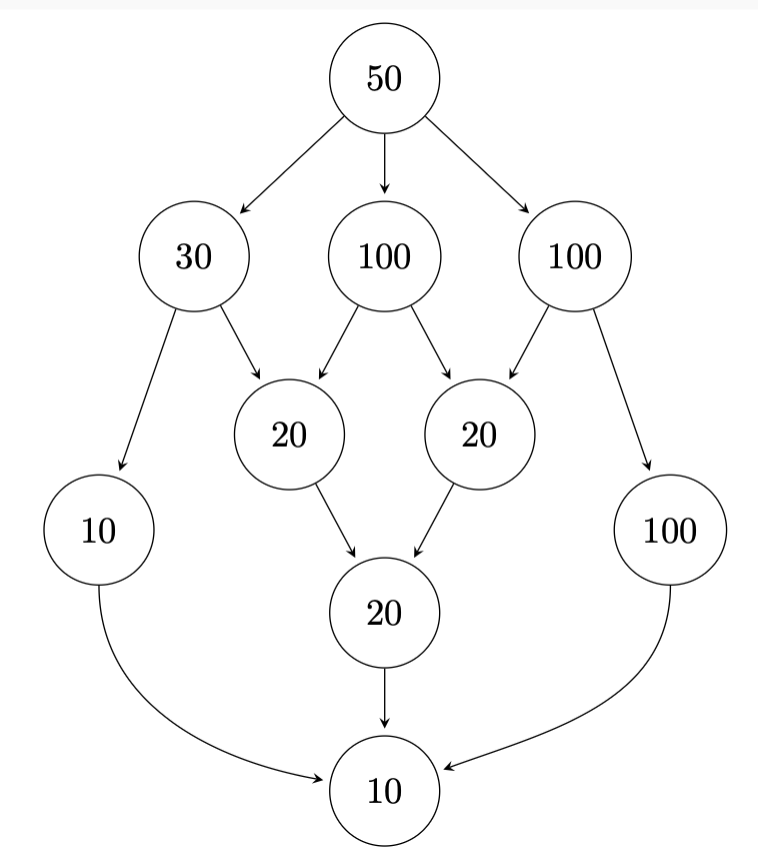
Given this example task-graph, how do we compute:
- Maximal Speedup
- Number of processors needed to achieve it
This graph has:
Thus the max speedup is .
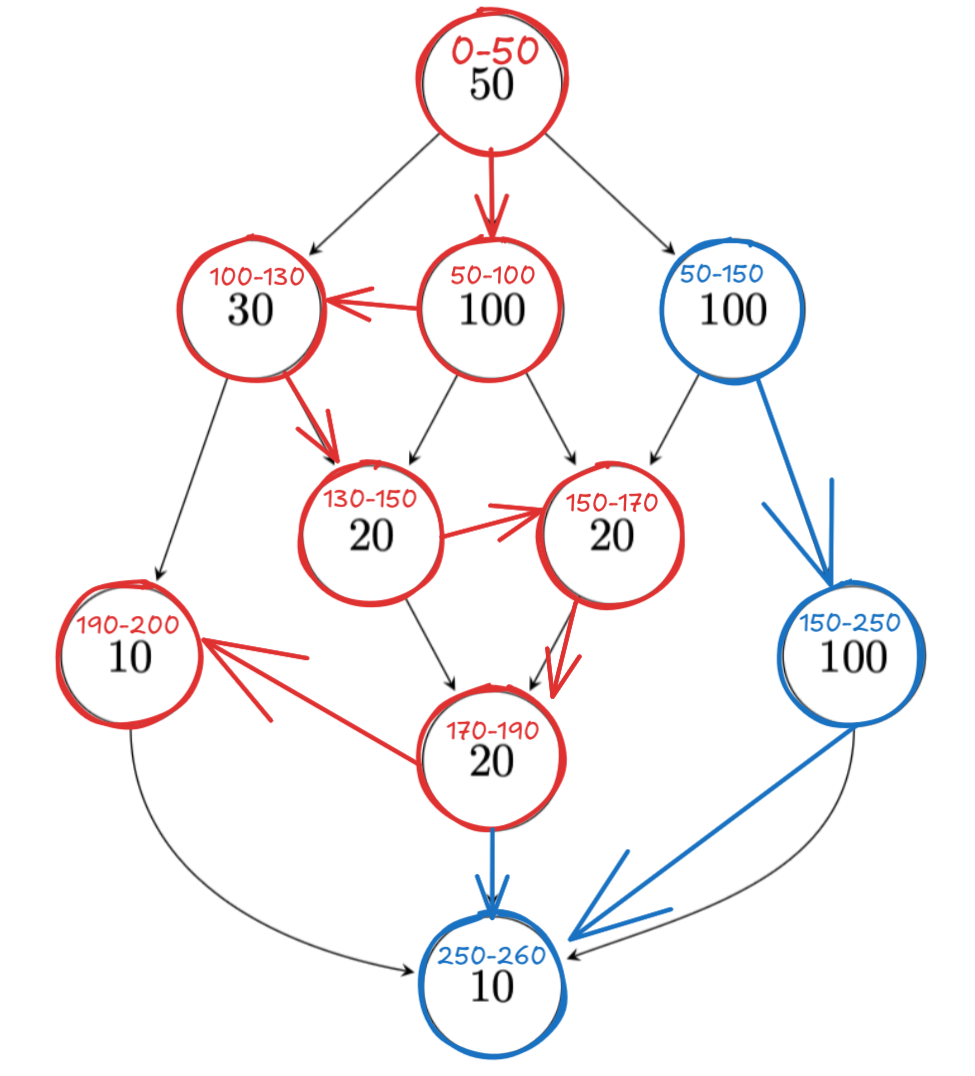
For this graph, 2 processors suffice. We just figure out which workloads each of them can take. Here with 2 we get total time 260, because of the chain that takes 260 on the right.
5.4.3 Concrete Runtime Bounds
We have the following bounds on work.
Parallel Time Bounds
Lower bound:
- Work law:
- Span law:
- — no scheduler can do better than this
Upper bound:
- Parallelizable work:
- DAG dependencies:
We get the following guarantees in Java.
THEOREM
The Fork/Join framework gives us an expected-time guarantee of asymptotically optimal:
using the FJ work-stealing scheduler.