2.0 Intro
A fundamental problem in combinatorics is determining the number of ways to choose k items from a set containing n distinct items. The method for counting depends on two crucial questions:
- Does the order of selection matter? (Is the selection ordered or unordered?)
- Can items be selected more than once? (Is the selection with replacement or without replacement?)
| Selection Type | Replacement? | Order Matters? | Formula |
|---|---|---|---|
| Tuple | Yes | Yes | |
| k-Permutation | No | Yes | |
| Combination / Set | No | No | |
| Multiset / Stars and Bars | Yes | No |
2.0.1 Ordered Selection with Replacement - Tuples
Derivation: This uses the basic multiplication principle of counting. We have independent choices to make, and each choice has possibilities.
- Total ways = (Choices for slot 1) (Choices for slot 2) (Choices for slot k)
- Total ways = ( times)
Formula: The number of ways is . We get an ordered list of length , often called a tuple.
- Possible 4-digit PIN codes using digits 0-9 (): .
- Possible outcomes when rolling a die 3 times (): . (e.g., (1, 6, 1) is different from (6, 1, 1)).
2.0.2 Ordered Selection without Replacement - k-Permutations
Think of filling ordered slots.
- For the first slot, we have choices.
- Since we cannot replace the chosen item, we only have choices remaining for the second slot.
- For the third slot, we have choices, and so on, until the -th slot, for which we have choices.
Derivation: Using the multiplication principle with decreasing choices:
- Total ways = (Choices for slot 1) (Choices for slot 2) (Choices for slot k)
- Total ways =
Formula: This quantity is often denoted as (falling factorial) or . It can also be expressed using factorials:
- Recall that .
Result Type: An ordered list of distinct items, often called a k-permutation of .
- Ways to award Gold, Silver, Bronze medals in a race with 8 competitors (): .
- Ways to arrange 3 distinct books from a collection of 5 on a shelf (): .
2.0.3 Unordered Selection without Replacement - Combinations / Sets
Intuition: How is this related to the ordered case without replacement (Case 2)? In Case 2, we counted sequences like (A, B, C) and (C, B, A) as distinct outcomes. However, if the order doesn’t matter, these sequences correspond to the same selection: the set . We need to figure out how many ordered sequences correspond to each unordered set.
Derivation:
- Start with the ordered count: ordered ways to select distinct items.
- Identify overcounting: There are ways to order distinct items (k choices for the first position, k-1 for the second, etc.).
- Correct for overcounting: Divide the ordered count by the overcounting factor
Formula: Number of unordered sets =
This is the binomial coefficient, read as “n choose k”:
Symmetry of Combinations
Note that .
Choosing items to include is the same as choosing items to exclude.
Result Type: An unordered set of distinct items, often called a combination.
Examples:
- Ways to choose 3 winners from 10 lottery tickets (order doesn’t matter) (): .
- Ways to form a 5-card poker hand from a 52-card deck (): .
4. Unordered Selection with Replacement - Multisets / Stars and Bars
Intuition: bins, representing the distinct types of items we can choose from. Choose a total of items.
Since order doesn’t matter and we can repeat types, this is like deciding how many times we choose type 1, how many times type 2, …, up to type , such that the total number of choices is .
Derivation (Stars and Bars technique):
- Represent Choices: Let “stars” represent the items we need to choose. Our goal is to divide these stars into groups, where each group corresponds to one of the types of items.
- Represent Dividers: To divide the stars into groups, we need “bars” (|). For example, if we have types and want to choose items, the sequence
**|*||**could represent choosing 2 items of type 1, 1 item of type 2, 0 items of type 3, and 2 items of type 4. - Combine Stars and Bars: Every possible selection corresponds uniquely to an arrangement of stars and bars in a sequence.
- Counting Arrangements: We have a total of positions in the sequence. We need to determine where the stars (or equivalently, the bars) go.
- Apply Combination Formula: This is now a combination problem (Case 3)! We need to choose positions for the stars out of the total positions. The number of ways to do this is . Alternatively, we could choose positions for the bars out of the total positions, which gives . These two binomial coefficients are equal.
Formula: We get an unordered collection where repetitions are allowed, often called a multiset.
Examples:
- Ways to choose 3 scoops of ice cream from 5 available flavours (): .
- Number of non-negative integer solutions to ( types/variables, total value/items): .
2.1 Grundbegriffe & Notationen
2.1 Diskreter Wahrscheinlichkeitsraum
Ein diskreter Wahrscheinlichkeitsraum ist bestimmt durch eine Ergebnismenge von Elementarereignissen.
Jedem Elementarereignis ist eine (Elementar-)Wahrscheinlichkeit zugeordnet, wobei wir fordern, dass und
kann endlich oder unendlich (sogar überabzählbar unendlich) sein.
Ereignis
Eine Menge heisst Ereignis. Die Wahrscheinlichkeit eines Ereignisses ist definiert durch
Komplementärereignis
Ist ein Ereignis, so bezeichnen wir mit das Komplementärereignis.
Properties of Sets and Complements:
All Standard rules (Assoc., Identity, Distrib.) apply.
- (De Morgan)
- and
- and and
- and
Disjointification (useful for probability)
- : turns a union into a disjoint union
- : partition by
More generally, if partitions :
2.2 Funamental Properties
- ,
- Wenn so folgt
Für paarweise disjunkte Ereignisse gilt der folgende Satz.
2.3 Additionssatz
Wenn für die Ereignisse paarweise disjunkt sind, so gilt
Im allgemeinen Fall können wir mit der Siebformel arbeiten.
2.5 Siebformel
Für Ereignisse () gilt
Der Union-Bound (Boolsche Ungleichung) wird öfters genutzt, da er einfacher anzuwenden ist. Er folgt direkt aus der Siebformel.
Boolsche Ungleichung
Für Ereignisse gilt
Beweis:
- Sei
- Dann gilt (weil )
- Alle sind disjunkt und
- Per Additionssatz (weil alle disjunkt) gilt
Laplace Raum
In einem Laplace-Raum sind alle Elementarereignisse gleich wahrscheinlich. Deswegen gilt .
wird dann uniform verteilt genannt.
Man sagt auch, dass für alle die größtmögliche Entropie hat.
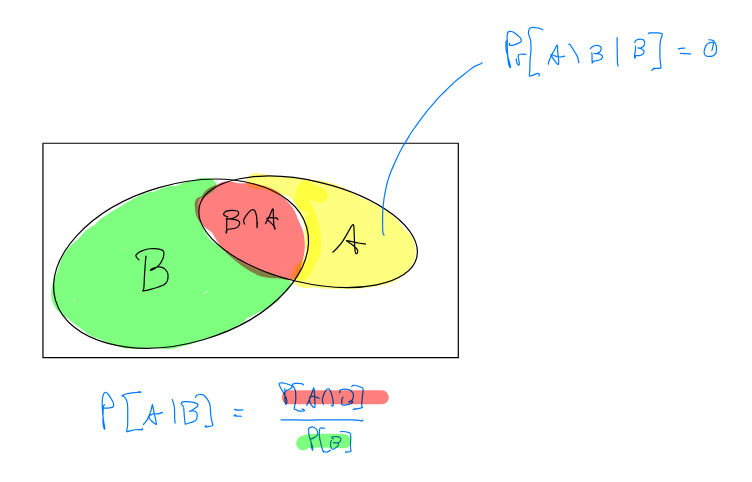
2.2 Bedingte Wahrscheinlichkeiten
Durch das Bekanntwerden zusätzlicher Information verändern sich Wahrscheinlichkeiten.
Wir notieren die Wahrscheinlichkeit von , wenn wir wissen, dass eingetreten ist.
Es gilt dann:
- und
- da ” ist eingetreten” keine extra Information liefert.
- Wenn eingetreten ist, kann nur noch eintreten. Daher ist proportional zu
2.8 Bedingte Wahrscheinlichkeit
und seien Ereignisse mit . Die bedingte Wahrscheinlichkeit von gegeben ist definiert durch
Die bedingten Wahrscheinlichkeiten bilden einen neuen Wahrscheinlichkeitsraum. Es gilt .
Damit gelten alle Rechenregeln auch für bedingte Wahrscheinlichkeiten, z.B.
Die Wahrscheinlichkeiten für alle Ereignisse (außerhalb ) werden auf gesetzt. Der Rest wird dann skaliert, damit die Summe wieder ergibt (mit , welcher in der Formel auftaucht).
2.10 Multiplikationssatz
Seien die Ereignisse gegeben. Falls ist, gilt
Beweis
- Da sind alle W’keiten wohldefiniert
- Wir schreiben um zu
- man sieht leicht dass sich hier kreuzweise alles bis auf herauskürzt.
2.13 Satz von der totalen W'keit
Die Ereignisse seien paarweise disjunkt und es gelte . Dann folgt
Proof
- da ist.
- Da alle disjunkt sind, sind auch und disjunkt.
- Dann gilt
- Wir wenden den Additionssatz an
2.15 Satz von Bayes
Die Ereignisse seien paarweise disjunkt. Ferner sei ein Ereignis .
Dann gilt für ein beliebiges :
Wir können mit dem Satz von Bayes gewissermaßen die Reihenfolge der Bedingung umdrehen.
2.3 Unabhängigkeit
2.18 Unabhängigkeit (2 Ereignisse)
Die Ereignisse und heißen unabhängig, wenn gilt
Wenn so können wir Umformen zu .
Intuitiv, wenn wir wissen, dass eingetreten ist so ändert sich nichts an der Wahrscheinlichkeit mit der wir erwarten.
Für mehr als 2 Ereignisse wird die Definition etwas komplexer:
- Beispiel: Wir werfen zwei ideale Münzen und : , .
-
und voneinander unabhängig, denn
-
und voneinander unabhängig
-
genauso und
-
Allerdings sind , , und zusammen nicht voneinander unabhängig, denn falls je zwei Ereignisse eintreten, so tritt auf keinen Fall das Dritte ein, also insbesondere .
-
Die paarweise Unabhängigkeit der Ereignisse genügt nicht → muss auch gelten
- Beispiel: Wir wählen eine zufällige Zahl zwischen 1 und 8 und betrachten die Ereignisse und . Außerdem sei .
- Aber $\Pr[A \cap B] = 1/8 \neq \Pr[A]\Pr[B]$, das heißt, $A$ und $B$ sind nicht unabhängig.
Wir brauchen also beide Bedingungen gleichzeitig.
Definition 2.22 (Unabhängigkeit von Ereignissen)
Die Ereignisse heissen unabhängig, wenn für alle Teilmengen mit gilt, dass
Eine unendliche Familie von Ereignissen mit heißt unabhängig, wenn dies für jede endliche Teilmenge erfüllt ist.
Lemma 2.23
Die Ereignisse sind genau dann unabhängig, wenn für alle gilt, dass
wobei und .
Beobachtung: Aus Lemma 2.23 folgt, dass für und unabhängig auch , oder , und , unabhängig sind.
Lemma 2.24
Seien , und unabhängige Ereignisse. Dann sind auch und bzw. und unabhängig.
Beweis: Die Unabhängigkeit von und folgt aus . Mit der Inklusion-Exklusion-Formel gilt:
und daraus folgt die Unabhängigkeit von und .
2.4 Zufallsvariablen
Definition 2.25 (Zufallsvariable)
Eine Zufallsvariable ist ein Abbildung , wobei die Ergebnismenge eines Wahrscheinlichkeitsraumes ist.
Wertebereich einer Zufallsvariable
Bei diskreten Wahrscheinlichkeitsräumen ist der Wertebereich einer Zufallsvariablen
Sei bzw.
Für ein beliebiges sei das Ereignis (wir drehen hier quasi um).
Beachte, schreibt man häufig als .
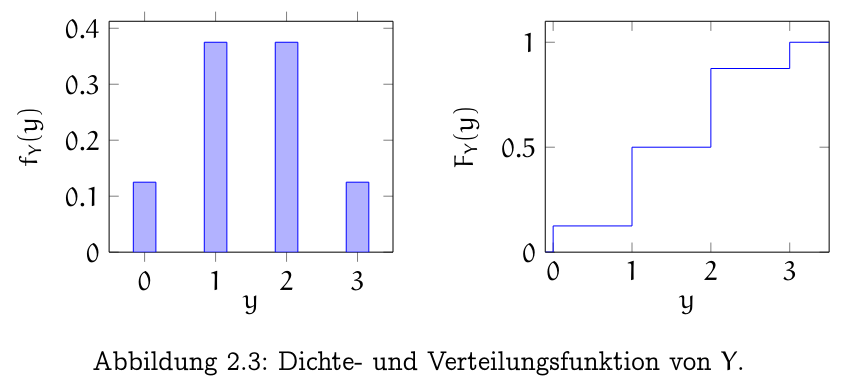
Dichefunktion
Die Funktion
nennt man Dichte(funktion) von .
Verteilungsfunktion
Die Funktion
heisst Verteilung(sfunktion) von .
Beachte, Dichte/Verteilungsfunktion beschreiben eine Zufallsvariable eindeutig.
2.4.1 Erwartungswert
Definition 2.27 (Erwartungswert)
Zu einer Zufallsvariablen definieren wir den Erwartungswert durch
Beachte, bei unendlichen Wahrscheinlichkeitsräumen kann diese Serie divergieren. Dann sagen wir, dass der Erwartungswert undefiniert ist.
Beispiel: Der Erwartungswert für die Anzahl “Kopf” bei dreimaligen Werfen einer idealen Münze ist
Lemma 2.29
Ist eine Zufallsvariable, so gilt:
Beweis:
Wir gewichten die Wahrscheinlichkeit mit dem Wert.
Satz 2.30
Sei eine Zufallsvariable mit . Dann gilt
Beweis: Nach Definition gilt
Bedinge Zufallsvariablen
Sei Zufallsvariable und , . Es gilt dann:
: Wahrscheinlichkeiten, mit denen die Zufallsvariable bestimmte Werte annimmt bezüglich der auf bedingten Wahrscheinlichkeiten berechnen.
Satz 2.32
Sei eine Zufallsvariable. Für paarweise disjunkte Ereignisse mit und gilt
Der Satz gilt auch für unendlich viele Ereignisse.
Beweis. Mit Hilfe des Satzes von der totalen Wahrscheinlichkeit rechnen wir nach, dass
Seien Zufallsvariablen. Für erhalten wir daher reelle Zahlen .
Sei eine Funktion ( reellen Zahlen wieder eine einzige reelle Zahl) dann ist wiederum eine Zufallsvariable: .
Für beliebige Funktionen und insbesondere auch für affin lineare Funktionen:
Wir schreiben dann .
Beispiel: Recursive Definition
- Let = number of flips until first heads with . Define = “first flip is heads.”
- Apply total expectation conditioned on :
- (done immediately)
- (memoryless: after tails, the process restarts identically, plus the one spent flip)
- Plugging into and solving yields .
This avoids computing directly. Technique generalizes to any renewal-type problem where failure resets the process.
Satz 2.33 (Linearität des Erwartungswerts)
Für Zufallsvariablen und mit gilt
Der Erwartungswert einer Summe ist die Summe der Erwartungswerte.
Beweis Lemma 2.29 sag . Dann gilt:
Hier haben wir außerdem benutzt, dass (für ).
Beobachtung 2.35 (Indikatorvariable)
Für ein Ereignis ist die zugehörige Indikatorvariable definiert durch:
Für den Erwartungswert von gilt:
2.4.2 Varianz
Definition 2.39 (Varianz)
Für eine Zufallsvariable mit definieren wir die Varianz durch
Die Grösse heisst Standardabweichung von .
Satz 2.40
Für eine beliebige Zufallsvariable gilt
Beweis: Sei .
- Nach Definition gilt
- Aus der Linearität des Erwartungswertes (Satz 2.33) folgt
- Damit erhalten wir
Satz 2.41
Für eine beliebige Zufallsvariable und gilt
Beweis:
- Mit Hilfe von erhalten wir
Linearität Varianz
Für unabhängig gilt
Proof: Sei . und unabhängig. .
- .
Dann ist .
Da für unabhängig, ist es korrekt.
Note Varianz kann nie negativ sein. Für unabhängig, mit , , and not !
Definition 2.42 (Momente)
Für eine Zufallsvariable nennen wir das -te Moment und das -te zentrale Moment.
Der Erwartungswert ist also das erste Moment.
2.5 Wichtige diskrete Verteilungen
2.5.1 Bernoulli-Verteilung
Eine Zufallsvariable mit und der Dichte
heißt Bernoulli-verteilt.
Man erhält diese Verteilung z.B. für einen Münzwurf.
Man schreibt dies auch als .
Bernoulli Expected Value and Variance
Für gilt
Proof Beide Ergebnisse sind einfach nachzurechnen, einfach in die Definitionen einsetzen. Wir wissen und und . Dann gilt:
und
2.5.2 Binomialverteilung
Werfen wir eine Münze mal und fragen, wie oft wir “Kopf” erhalten, ist binomialverteilt:
Dies gilt, da wir Zählen, wie viele Möglichkeiten es gibt auf Würfe, genau mal “Kopf” zu erhalten: .
Wir schreiben .
Binomial EV and Var
Für gilt
Proof
- Elegant:
- Wir schlüsseln in unabhängige Bernoulli-verteilte Variablen auf. Dann gilt durch Linearität von sowohl als auch :
- Induktion
- ähnlich wie oben, nur weniger direkt. Für den ersten Wurf bedingen wir auf und . Dann gilt:
2. per Induktion runter auf $n$ bleibt dann $np$.
3. Direkt
1.
2. dann faktorisieren wir raus.
3.
1. wir starten von da wir wissen dass für , gilt also fällt der term weg.
4. re-index
5. Dann können wir ein rausfaktorisieren und es bleibt was genau die binomische Formel ist
6. Da gilt und wir das für , und haben bleibt .
1. Man kann das alternativ auch so sehen, dass die Summe die “density” der Funktion über alle Werte ist und deswegen sein muss.
2.5.3 Geometrische Verteilung
Wenn wir die Münzwürfe solange wiederholen, bis wir Erfolg haben, dann ist die Zahl der Würfe geometrisch verteilt (sofern alle unabhängig und gleich-wahrscheinlich sind):
Dies gilt, da wir Mal mit W’keit Kopf werfen, und Mal Zahl werfen, also insgesamt genau Mal für .
Wir schreiben .
THEOREM
Sei dann gilt
Proof:
- Easy, using a practical property: We use the fact that .
- for the geometric series , i.e. k failures at least.
- That gives us
- Gedächtnislosigkeit:
- which gives where the as the coin has no memory, it’s just as likely after the second one.
- This easily gives us and thus the expectation.
- Hard, directly:
- we then expand that sum and start from 1 as it’s for : and pull out the .
- we write the sum .
- Then
- and then by reindexing the second sum.
- Then
- and add the one back in:
- Thus and .
- Finally giving us .
Verteilungsfunktion für Geometrische Verteilung
Wir können für schreiben
Die geometrische Verteilung ist Gedächtnislos. Das heißt, dass die W’keit nach dem ersten oder tausendsten Wurf “Kopf” zu kriegen, immer gleich ist.
2.45 Gedächtnislosigkeit
Ist so gilt für alle
Proof: Für die Verteilungsfunktion von gilt . Somit ist . Dann gilt
2.5.3,5 Negativ Binomialverteilt
Bei der geometrischen wird das Experiment solange wiederholt, bis der erste Erfolg eingetreten ist. Wenn wir auf den -ten Erfolg warten, nennen wir negativ binomialverteilt mit Ordnung .
Für gilt da wir auf den ersten Erfolg warten.
Intution die Anzahl der Versuche bis zum -ten erfolgreichen Experiment.
- dann genau erfolgreiche und nicht erfolgreiche
- Per Definition das letzte Experiment erfolgreich
- Erfolge beliebig auf die restlichen Experiment verteilt
- Dafür gibt es Möglichkeiten, jede tritt mit ein.
Wir haben also die Dichte
Erwartungswert Negativ Binomialverteilt
Sei die Zufallsvariable für das -te Geometrisch verteilte Experiment. Dann gilt
Intuition Erwartungswert Wir starten quasi nach jedem Erfolg “neu”. Die einzelnen Teile sind jeweils geometrisch verteilt. Nach der Linearität des Erwartungswertes ist also die Summe.
2.5.3,7 Coupon-Collector
Wenn es insgesamt “Sammelbilder” gibt, wie viele muss ich kaufen, bis ich alle besitze. Sei die Anzahl Runden, bis alle erhalten wurden.
Wir teilen den Prozess in Phasen. Phase ist die Anzahl Runden von Coupons bis zum neuen Coupon . Sei die Anzahl Runden in Phase .
- Linearität des Erwartungswertes:
In der Phase gilt: wir haben unterschiedliche Coupons - Jede Runde ist die W’keit
- es gibt Coupons die wir noch nicht haben
- Dadurch gilt
- Die Anzahl Runden ist dann
Also gilt .
Dann ist . Sei , dann geht mit von , .
Dann gilt wo die -te harmonische Zahl ist.
Wir wissen und damit gilt .
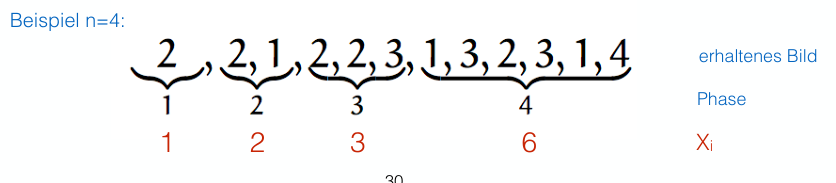
2.5.4 Poisson-Verteilung
Modelliert Menge an seltenen Ereignissen, während einer fixen Zeitspanne, wenn die Ereignisse mit konstanter Durschnittsrate und unabhängig auftreten. Example: Herzinfarkte in der Schweiz.
Wir definieren für eine Rate die die Verteilungsfunktion wie folgt
Poisson EV and Var
Für gilt
Proof: We can derive both expectation and variance from the pmf using the explicit definitions:
Poisson als Grenzwert der Binomialverteilung:
Another standard way to see the Poisson distribution is as “Balls and Bins”: we throw balls independently into bins. is the number of balls in the first bin.
- For each the probability is , so
What happens to as ?- As
- as
Thus we get
So more generally for , so , .
2.6 Mehrere Zufallsvariablen
Für zwei Zufallsvariablen und über demselben Wahrscheinlichkeitsraum schreiben wir
Gemeinsame Dichte
Die Funktion
heisst gemeinsame Dichte der Zufallsvariablen und .
Wir können aus der gemeinsamen Dichte wieder die Dichten der einzelnen Variablen ausrechnen:
Randdichte
Die Randdichte erhält man durch Summation über die jeweils andere Variable:
Dies folgt direkt aus der totale Wahrscheinlichkeit, da die Ereignisse eine disjunkte Zerlegung des Wahrscheinlichkeitsraums bilden.
Gemeinsame Verteilung
Die gemeinsame Verteilung zweier Zufallsvariablen und ist
Die Randverteilung ergibt sich als .
Example: Skatblat: ziehe aus 32 Karten 10 Karten als Hand und 2 als Skat.
= Anzahl Buben in der Hand, = Anzahl Buben im Skat. Gemeinsame Dichte:
Daraus folgt z.B. , da es insgesamt nur 4 Buben gibt.
2.6.1 Unabhängigkeit von Zufallsvariablen
2.52 Unabhängigkeit
Zufallsvariablen heissen unabhängig genau dann, wenn für alle gilt:
Äquivalent: , d.h. für unabhängige Variablen ist die gemeinsame Dichte gleich dem Produkt der Randdichten.
Note, für gilt die Definition genauso, nur dass dann beide Seiten sind.
2.53 Produkteigenschaft für Mengen
Sind unabhängige Zufallsvariablen und beliebige Mengen, dann gilt
Proof: Es genügt, zu betrachten. Dann:
2.54 Teilmengen bleiben unabhängig
Sind unabhängig und , dann sind ebenfalls unabhängig.
Intuitiv: sind unabhängig, so gilt dies auch für z.B.
Proof: Setze für und für . Dann ist für trivialerweise erfüllt und Lemma 2.53 liefert die Produktzerlegung:
Beachte, dass wir für im Produkt ignorieren können, da gilt.
2.55 Funktionen unabhängiger Variablen
Seien reellwertige Funktionen. Wenn unabhängig sind, dann sind auch unabhängig.
Proof: Für definiere . Mit Lemma 2.53:
Beachte, Die Umkehrung gilt nicht: auch abhängige können nach Anwendung einer konstanten Funktion unabhängige Bilder haben. Siehe z.B. die konstante Funktion .
2.6.2 Zusammengesetzte Zufallsvariablen
Aus lässt sich durch eine Funktion eine neue Zufallsvariable konstruieren. Die Wahrscheinlichkeiten berechnen sich wie gewohnt:
2.58 Faltung / Konvolution unabhängige Zufallsvariablen und sei . Dann gilt
Für zwei
Intuitiv: Wir summieren über alle möglichen Paare basically.
Proof: Mit dem Satz von der totalen Wahrscheinlichkeit:
Example: Poisson-Stabilität: Sind und unabhängig, so gilt mit dem Binomialsatz:
d.h. . Die Poisson-Verteilung ist stabil unter Faltung.
2.6.3 Momente zusammengesetzter Zufallsvariablen
2.60 Linearität des Erwartungswerts
Für Zufallsvariablen (beliebig, auch abhängig) und mit gilt
Beachte, damit oberes gilt, müssen die Zufallsvariablen nicht unabhängig sein!
2.61 Multiplikativität des Erwartungswerts
Für unabhängige Zufallsvariablen gilt
Proof: Basisfall . Mit der Unabhängigkeit:
Wobei dank Unabhängigkeit hält.
Beachte, die Unabhängigkeit ist notwendig: für gilt im Allgemeinen (sonst gilt Varianz = 0).
2.62 Varianz der Summe
Für unabhängige Zufallsvariablen und gilt
Proof: Basisfall , .
- Berechne und und subtrahiere.
- Unabhängigkeit liefert , wodurch sich die gemischten Terme aufheben
Für abhängige Variablen gilt die Formel im Allgemeinen nicht. Gegenbeispiel: ).
Varianz eines Produktes
Beachte, für Produkte gilt selbst bei Unabhängigkeit nicht allgemein, dass .
Zusammenfassung
| Property | Always True? | Conditions Required |
|---|---|---|
| ✅ Always | None | |
| ✅ If independent | independent | |
| ✅ If independent | (pairwise) independent | |
| ❌ Not in general | Fails even if independent |
2.6.4 Waldsche Identität
In vielen Anwendungen ist die Anzahl der Summanden selbst eine Zufallsvariable (z.B. Laufzeit eines Algorithmus, der eine zufällige Anzahl Phasen durchläuft).
Waldsche Identität (Satz 2.65)
Seien und unabhängige Zufallsvariablen mit , und sei wobei unabhängige Kopien von sind. Dann gilt
Proof: Mit dem Satz von der totalen Wahrscheinlichkeit und der Linearität:
Der entscheidende Schritt ist (Linearität, da jetzt eine Konstante ist).
Example: Eine Münze mit Kopf-Wahrscheinlichkeit wird so lange geworfen, bis das erste Mal Kopf erscheint (, ).
Dann wird -mal weitergeworfen, = Anzahl Kopf. Die Waldsche Identität liefert direkt .
2.6.Exkurs Bedingte Zufallsvariablen
Bedingte Zufallsvariablen
Sei eine Zufallsvariable und ein Ereigniss.
Dann gilt
Wir wollen also nur die Wahrscheinlichkeit von , gegeben dass Eintritt, wissen.
Es gilt dann genauso wie für Ereignisse der Satz der totalen W’keit:
Satz der totalen W'keit (ZV)
Für disjunkt mit und gilt
Proof:
where the first inequality follows directly from the Satz der totalen W’keit.
2.7 Abschätzen von Wahrscheinlichkeiten
Der Erwartungswert einer ZV kann stark von dem erwarteten Ergebnis für einen einzigen Wurf abweichen (z.B. ZV die mit sehr kleiner chance sehr großen Wert annimmt).
2.7.1 Die Ungleichungen von Markov und Chebychev
2.67 Markov-Ungleichung
Sei eine Zufallsvariable mit (nicht-negativ). Dann gilt für alle :
Äquivalent: .
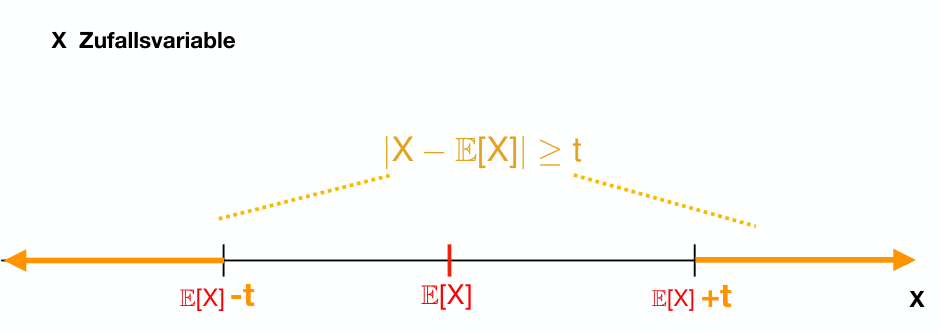
Proof:
Die Ungleichung ergibt sich im wesentlichen durch das Weglassen einiger Summanden (denen mit ).
Wenn wir die Markov-Ungleichung auf die Varianz anstatt den Erwartungswert anwenden, erhalten wir die Chebychev-Ungleichung.
2.68 Chebyshev-Ungleichung
Sei eine Zufallsvariable und . Dann gilt
Äquivalent: .
Proof: Es gilt
dies folgt da wir immer die Ungleichung innerhalb des manipulieren können und .
- Die ZV ist nicht-negativ und (da ).
- Durch anwenden der Markov-Ungleichung kommen wir dann zu:
Intuitiv, je kleiner die Varianz, desto größer ist die W’keit dass nur Werte innerhalb eines Intervalls annimmt.
Je kleiner die Varianz, desto konzentrierter ist um seinen Erwartungswert.
Example: Coupon-Collector: Sei die Anzahl Käufe beim Coupon-Collector-Problem mit Bildern. Es gilt und . Chebyshev liefert für :
2.7.2 Die Ungleichung von Chernoff
Wenn wir mehr über die Verteilung wissen, können wir bessere Schranken erreichen, als nur die Markov- und Chebychev-Ungleichungen.
Für Summen von Bernoulli-Variablen gibt es wesentlich schärfere Schranken:
2.70 Chernoff-Schranken
Seien unabhängige Bernoulli-Variablen mit , und sei . Dann gilt:
Proof: iii) Wende die Markov-Ungleichung auf an (streng monoton, also ).
Mit:
- der Unabhängigkeit und Satz 2.55 (Funktion von unabhängigen sind wieder unabhängig) sind unabhängig
- Satz 2.61 (Erwartung ist Multiplikativ für unabhängige) liefert:
Für gilt , woraus folgt. Die Teile (i) und (ii) folgen analog mit .
2.8 Randomisierte Algorithmen
Ein normaler Algorithmus, geschrieben als gibt für den gleichen Input immer den gleichen Output aus.
Einem randomisierten Algorithmus stellen wir außerdem noch Zufall, in der Form von -Zufallsbits zur Verfügung, geschrieben als .
Monte-Carlo Algorithmus
Für einen Monte-Carlo Algorithmus gilt, dass:
- die Korrektheit eine ZV ist
- Laufzeit fix ist
Immer schnell, mit meistens richtiger Antwort.
Las-Vegas Algorithmus
Für einen Las-Vegas Algorithmus gilt, dass:
- die Ausgabe immer Korrekt ist (nicht vom Zufall abhängt)
- Die Laufzeit eine ZV ist
Immer richtig, jedoch nur meistens schnell.
Alternative Definition: Las-Vegas:
Wir können einen Las-Vegas Algorithmus auch ??? ausgeben lassen, wenn er sich nicht sicher ist. Dies wäre auch eine “korrekte” Ausgabe. Die Garantie ist dann: “wenn die Antwort nicht ??? ist, ist sie korrekt”.
Arten von LV-Algos:
- Wiederholen bis nicht mehr
???rauskommt - Für laufen lassen, wenn bis dahin nichts kommt dann
???
Note, wir können jeden LV-Algo in einen ??? LV-Algo konvertieren, in dem wir in fix laufen lassen, und dann aborten. Falls er JA/NEIN zurückgegeben hat das ausgeben, sonst ???.
2.8.1 Reduktion der Fehlerwahrscheinlichkeit
2.72 Las-Vegas-Fehlerreduktion
Sei ein randomisierter LV-Algorithmus mit .
Dann gilt für den Algorithmus , der bis zu mal wiederholt (und bei der ersten Nicht-???-Antwort abbricht):
Note, heißt, dass der Algorithmus maximal mit W’keit ??? ausgibt.
Proof: Die Wahrscheinlichkeit, dass alle Aufrufe ??? liefern, ist .
Für einen MC-Algo ist die Reduktion der Fehler-W’keit nicht ganz so einfach. Er muss eine der folgenden Bedingungen erfüllen:
- Der Algorithmus hat einen einseitigen Fehler.
- (besser als Zufall) (zweiseitiger Fehler)
2.74 Monte-Carlo mit einseitigem Fehler
Sei ein Algorithmus mit für Ja-Instanzen und für Nein-Instanzen.
Der Algorithmus wiederholt bis zum ersten Nein (maximal mal). Dann gilt:
Wenn der Algorithmus also bei “Ja-Instanzen” immer korrekt “Ja” ausgibt, hat er einen einseitigen Fehler. Wir wiederholen also bis entweder “Ja” kommt (dann ist sicher “Ja” richtig) oder “Nein” sehr wahrscheinlich wird.
2.75 Monte-Carlo mit zweiseitigem Fehler
Sei .
Der Algorithmus macht unabhängige Aufrufe und gibt die Mehrheitsantwort aus. Dann gilt:
Proof: Sei die Anzahl korrekter Antworten.
-
- Es gilt
- durch sehr viel handwaving gilt .
- Wir wollen begrenzen als kleiner als .
- Chernoff (ii)
- von vorher wissen wir das gilt
- also .
- Da gilt auch weil .
- Also gilt
- und wir wollen
Deswegen müssen wir wählen.
2.76 Fehlerreduktion für Optimierungsprobleme
Sei .
Der Algorithmus macht Aufrufe und gibt das Beste zurück. Dann gilt .
Proof: Die W’keit das bei Aufrufen kein einziges Mal kommt ist höchstens
wir benutzen und .
2.8.2 Sortieren und Selektieren
We know that for a worst-case input (inversely sorted list), when always choosing the last element as a pivot, quicksort needs time (as each partition splits off 1 element).
This randomised Quicksort procedure has expected runtime.
By randomly choosing the pivot element, we can reduce this to on average. That is we want to show that
Let be the number of comparisons. For . For we have recursively
by assumption all elements are unique. Thus , as each is equally likely to be chosen. We notice does not depend on or , but only on the length .
Then we define
for easier handling.
Then for we have and .
By subtracting we get
and thus
By using induction . We can factor out the and then we get the harmonic sequence (which is . Thus
as .
We also look at Quickselect: it has linear runtime.
Quickselect allows us to find the k-th smallest element in an array. It does this without sorting, by partitioning the array and choosing the part in which the k-th smallest must then be.
This has linear runtime, which we want to prove:
We define a random sequence which defines the sequence of partitioning choices we make to find the target element.
From the algorithm we see that by construction and that .
Then the number of comparisons for a call of Quicksort is as each call does exactly comparisons.
We now want to bound the total number of comparisons. We do this by sorting them into buckets, each of the remaining elements.
We define as the number of calls for which .
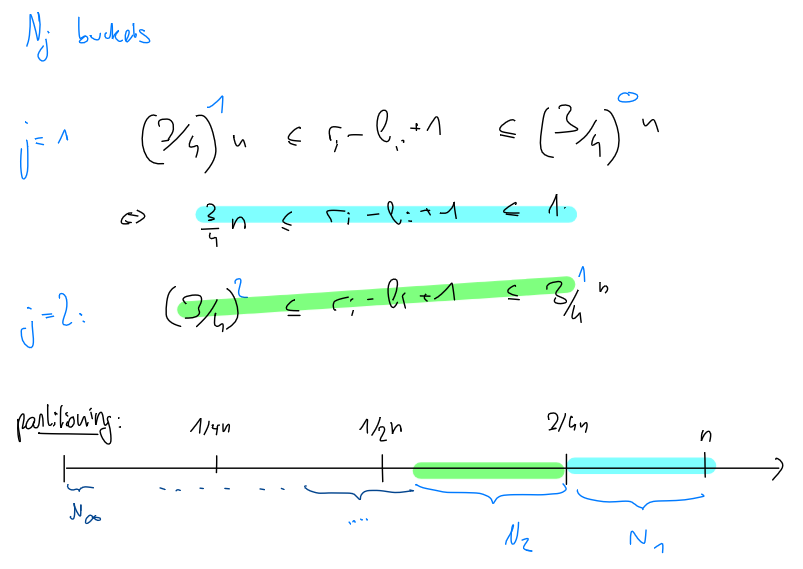
Since is the upper bound for each call in , we know
By the linearity of expectation
what do we know about ? If the pivot is chosen in the middle half of the array, then or are smaller than . As it’s uniform, the probability of that happening is . Thus .
Therefore
Note: for a practical implementation where there can be non-distinct integers, we need tripartition using the “dutch flag algorithm” for in place partitioning into <, ==, >.
https://leetcode.com/problems/kth-largest-element-in-an-array
2.8.3 Miller-Rabin-Primzahlentest
For RSA or other crypographic applications, we often need primes of multiple thousands of bits. Usual procedure: choose random number of that length → check if prime.
Naively, this can be done by checking all numbers . But this is very inefficient for such large numbers (imagine 4096 bits).
We want an algorithm that is polynomial in , (so polynomial with regards to the number of digits, i.e. in ).
Naive approach Choose randomly, check for certificates
- we choose a random number in
- check if .
- If yes, we found a certificate for the non-primality of .
(This is an example of a las-vegas algorithm with a one-sided error.)
This does not work well for numbers a composite of two prime numbers. Then the chance we find one of them is , so we need to find one.
Using Fermat We know from diskmath that if prime, then
(Fermat’s little theorem).
So if we find an s.t. , then we know for sure that is not prime.
Note: we can exponentiate efficiently using binary exponentiation.
Carmichael Numbers: There are numbers that are not prime, but for all s.t. satisfy . The smallest such number is .
- thus we don’t find any certificates we wouldn’t already find by computing the gcd for a large number of random .
As there are an infinite amount of these Carmichael numbers, we still have to refine our approach.
→ See Why are there Carmichael Numbers.
Miller-Rabin:
- if prime, for a field with addition and multiplication.
- We take
- In a field, there are no zero-divisors
- Thus iff. ( or )
- We can use this to our advantage. If we find an satisfying this with , we know there is a zero-divisor not a field not prime
We incorporate this into the algorithm in the following way.
- we write where odd (i.e. choose the biggest possible)
- if prime,
- Therefore (or ) as proven before
- We iterate over .
- Either for all
- or there is an s.t.
- if both conditions are violated, is not prime and we found our certificate .
- intuitively: if we find an with s.t. and then we found a with for → not a field.
In other words, the chain of numbers we get when running the algorithm can be
- But never have in it
Why can we have ? because and there is nothing that forbids this. - is prime yet
Example: so with and .
- …
which is a valid chain. Thus 97 is prime
2.8.4 Target-Shooting
Gegeben einer Menge und einer Untermenge unbekannter Größe, wie groß ist . Wir nehmen an wir haben für die Indikatorfunktion (we need efficiently computable).
Algorithmus: Für geeignete Wahl, wähle Elemente auf zufällig aus und return zurück: .
Let . Because of uniform and independent choice of , the random variables are independent Bernoulli variables with .
Thus
Therefore , as , independent of the choice of . The variance:
is dependent on however.
Let . How large must be for the algorithm to return an answer in with probability ?
Target Shooting
Let . If then the returned value is within
with probability at least .
Proof:
- Because it suffices to show
- we note , this is equivalent to
- As are independent bernoulli variables, we can use the chernoff bounds:
2.8.5 Finden von Duplikaten
Lecture 8: Hashing with Chaining (MIT OCW)
Lecture 9: Table Doubling, Karp-Rabin (MIT OCW)
Lecture 10: Open Addressing, Cryptographic Hashing (MIT OCW)
Lecture 8: Randomization: Universal & Perfect Hashing
— TODO: Update with notes from “Algorithmen” book about hashing types (p. 253)
- see chaining vs. open addressing
- universal hash functions
How do we find duplicates in an array?
Naive approaches
- we could sort the array in
- and check for duplicates by scanning again in
For collecting all duplicate pairs, we will then need time. Thus total complexity .
However, some real world constraints might be that the elements in the array are large (files for example) that we can’t simply sort. Memory accesses and comparisons are very slow in that case.
We can use hash-functions in this case. A hash-function needs to be efficiently computable and uniformly distribute the elements, i.e. for all .
We can now solve the problem by adding each element to the hashmap and counting the duplicates at the end:
- for each element , hash and create pair
- sort them by hash
- iterate through the sorted list. If and have then we have our candidate duplicate pair
- For each pair, we perform a full comparison.
To estimate the runtime, we need to calculate the expected number of collisions:
- For iff. there is a collision with . Then
- this is because each element is mapped to a uniformly random value in the bits and there are other values.
- Thus is the probability of hashing to a different value. We do it times to get the prob that all hash to a different value
- Then that to find the prob that there is at least 1 collision
- Thus
- If we choose such that holds, we’ll only expect an number of collisions.
Therefore the hashmap duplicate counter takes only time, for the sorting of the hashmap.
2.8.6 Bloom Filters
https://samwho.dev/bloom-filters
Bloom filters are a probabilistic data structure. They have a one-sided error. They
- can give false positives
- but never false negatives.
It does this by using bits and hash functions. On insertion, we set bits, one for each hash function. To check if the filter contains an element, we check if those bits are set (this might return a false positive). We cannot delete however.
Estimating the probability of false positives: A false positive occurs when was not previously inserted but (where is the bit set by hashing with hash function ).
Let if is a false positive, otherwise 0. We want to estimate . Let be the number of bits in the bloom filter.
- Suppose items have been inserted before processing . Each item set bits. So in total, up to bits might be set.
- (probability bit not set and that for repetitions)
- Then for , the probability that all hash bits are is .
- Worst case . And as each bit is independent, the sum can be collapsed to . Therefore
So the false positive rate is minimised for . If we want to minimise the false positives, we choose and .
Counting Bloom Filters By instead counting the number of times a certain bit has been activated, we can make removal possible.
- this introduces the possibility of false negatives however
ifadd(a)set bit 0, 1 andadd(b)set bit 2, 3. thenremove(c)unsets 1, 2 → even thoughcwas never added, it removed something. Now iffind(a)is called it will return a false negative.
Extra
Why are there Carmichael Numbers
For a group there is
- the order the number of elements
- the order of each element .
Lagrange tells us that .
For cyclic groups, these coincide: - see where .
For a squarefree , we have
It’s generally not cyclic, it’s a direct product. Now, the order and the order/exponent diverge:
- Order
- order of each element
- aside: why lcm? because needs to hit simultaneously. So the exponent has to be the lcm of the individual orders.
For , the order of each component is , thus the product has but the lcm is .
Thus every element satisfies
- aside: why lcm? because needs to hit simultaneously. So the exponent has to be the lcm of the individual orders.
And because , for all numbers. Thus is a Carmichael.